ACORN Implemented
The Project ACORN [1] is an eLib [2] funded project looking at the provision of electronic short loan reserves in a University library environment. The project has three main partners; Loughborough University [3], Swets & Zeitlinger b.v. [4] and Leicester University [5]. This paper provides an overview of the ACORN system and a description of the technical implementation of the system in the Pilkington Library at Loughborough University.
ACORN System Model
The ACORN system model is the abstract model behind the real implementation. The model contains a number of separate modules that communicate with one another in order to provide the services required of the ACORN system. Figure 1 shows the various components in the system model and how they inter-relate with one another.
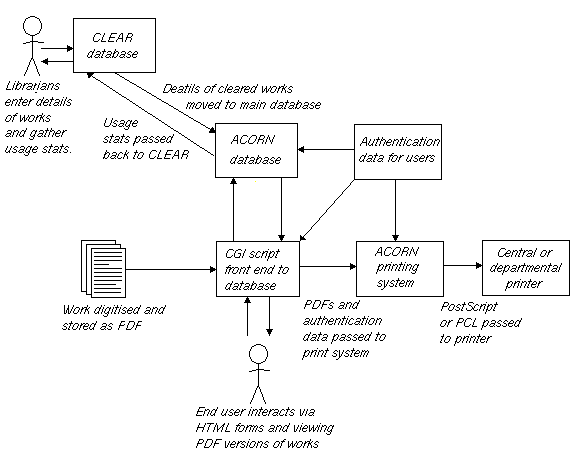
Figure 1: The ACORN system model
ACORN really has two distinct user interfaces. There is an interface for the librarians and systems staff see that allow them to enter and remove works, record copyright clearance data and retrieve usage statistics, and there is also the interface that the end users see to allow them to actually make use of the ACORN system.
For a work to appear in the ACORN system, it must first appear on a reading list provided by a member of academic staff. The details of the work are entered into the copyright clearance database (CLEAR) and a librarian then attempts to gain a copyright clearance from the copyright holder of the work (usually a publisher). The database contains details of which works have had clearances given to them and under what conditions. As different publishers impose different charges and access restrictions, it is important that the copyright clearance database is fairly flexible in what it accepts.
Once cleared, the original work is digitised and is placed in the main ACORN database. It is now possible for an end user to gain access to it. However these end users must pass through an authentication system to ensure that they are allowed to access the requested documents. If they are, the system will allow them to view the documents and/or print them.
Viewing a document is simply a matter of returning an electronic copy in a suitable format to the end user’s machine and then recording the date, time, user and document details in the main ACORN database. Printing is a little more complicated. The abstract model includes a print system that the user must interact with in order to choose an appropriate printer. This print system then checks that the user is allowed to use the chosen printer and if they are, generates a print job for the requested document and then submits it to the print system on the user’s behalf. The main ACORN database also maintains a record of what pages of a document an end user has printed and when, so that statistics can be gathered and publisher’s copyright terms obeyed when they charges based upon the number of pages printed.
The following section will now give a more in depth technical explanation of how the ACORN system model has been realised at Loughborough. It should be noted that this is just one possible implementation of the model; its purpose is to show that the model is reasonable and to provide a working service at Loughborough. If the ACORN system model is used at another site, different choices may need to be made based on the existing information systems infrastructure within which the system must operate.
CLEAR Copyright Database
CLEAR (Copyright-Licensed Electronic Access to Readings) is the Project Acorn Copyright Management system, which was developed by the project team, using Microsoft Access. The system is used on a PC running Microsoft Windows 3.11. The system has been designed to handle all the aspects of Copyright Management relevant to the project, ranging from storing information about reading list articles, the modules that they come from and the tutors who teach those modules, to generating reports and graphs of management information about the electronic articles and their usage.
The system was used in conjunction with Microsoft Word to produce permission request letters to publishers, and was also used to produce address labels for the envelopes.
The information from the CLEAR database is uploaded into the Sybase database, and usage data is downloaded from the Sybase database to be analysed by the CLEAR database.
Main Sybase Database
The main ACORN database has been implemented using Sybase running on a SPARC station 5 under Solaris 2.5.1. Sybase was chosen as it is the underlying database technology used in the campus Talis OPAC, and therefore there was already local experience and tools available to make use of the database. The server itself physically lives in the Computer Centre machine room, along with the OPAC machines, where it can be easily backed up along with the other central services machines.
The main ACORN database actually has a relatively simple entity relationship model and this was mapped out on paper before the appropriate tables were created within Sybase. Obviously if the ACORN system was implemented at another site, Sybase may not be the best choice. It is relatively expensive, especially if used outside of the educational community, and other sites may already have another relational database available. To aid portability, the Loughborough implementation of the ACORN system model has shyed away from using any of the special features of Transact-SQL and has stuck instead to the standard aspects of the ANSI-SQL query language.
An ER diagram for the initial ACORN service was created to capture the needs of the main database. This diagram explicitly states that it is journal articles that are being considered and separates the details that apply specifically to that form of work from the other information needed by the system. This separation has subsequently allowed us to easily add to the ER diagram to support other types of work such as book chapters and examination papers. It is hoped that the later of these will be actually implemented at Loughborough sometime in the near future.
In the main database, the primary key used to deal with actions occuring to a work is the WORK_ID. This is a unique numeric identifier that is identical to the WORK_ID’s that are used inside our Talis OPAC’s database. Using the Talis WORK_ID’s is convenient as it means we do not have to generate these ourselves and it also makes linking into the ACORN system from our Talis WebOPAC relatively straight forward.
Of course if ACORN is ported to another site, Talis and it’s WORK_ID’s may not be present. If another library OPAC is in use, it is likely to have functional equivalents nonetheless, and these should probably be used as the primary access keys to facilitate easier linking between the OPAC and the ACORN system. If no OPAC is in use, the unique primary keys would have to be generated by the ACORN software at some point - the CLEAR database already does this for all the articles that are entered in to it.
Web front end to the Sybase Database
Once the data detailing works is in the Sybase database, the end users must be provided with some way of accessing it. In the Loughborough implementation of ACORN, the front end is provided by a web browser and an Adobe Acrobat PDF file viewer. The user interacts with the main Sybase database through a Common Gateway Interface (CGI) script that generates and processes HTML forms. The CGI script is written in the Perl programming language as this is ideally suited to the I/O processing, string handling and database interaction that is required in this instance. The use of the web as a front end means that the end users can make use of familiar, common tools and the amount of work that the system developers have had to make on generating the front end is quite low.
The end user has two entry points into the initial ACORN system installed at Loughborough. Firstly, they can come in via the web pages of their particular department, from the main University Web Pages. This provides an HTML document listing departments that run modules that have works in the ACORN system. From this document they can then get to other HTML documents that allow them to select first the module that they are interested in and then the actual work that they want. The other way of getting in to the ACORN system is via the library’s existing Talis WebOPAC by following a link from the work detail document. This link is generated from a note held in the Talis OPAC that points out that there is an electronic version of the document available. Note that either method can be used by lecturing staff to provide their own sets of links in online course material, thus allowing ACORN to be integrated in the teaching material presented to the students.
Whichever way the user comes into the ACORN system they will have to supply authentication information if they wish to view or print the work. This is needed to comply with many of the publishers copyright clearance requirements and also to allow usage of the system to be tracked. In the Loughborough implementation of the ACORN system model, it was decided to implement a simple security mechanism based on that which was deployed in the Talis WebOPAC prototype.
The authentication information that the ACORN system requires is the user’s central services username and password. These are only prompted for at the user’s initial contact with the ACORN system, or if they spend too long between interaction. The usernames and passwords are currently sent in plaintext, but as this how they are transported using telnet anywaay, this is not currently a great concern. If this did turn out to be a problem in the future, the web server could easily be converted into using something like SSL to provide an encrypted transport for the HTTP transactions.
Once the script on the main ACORN server gets a username and password it encrypts the password using the crypt(3) and compares it with the encrypted password from the Central Services password file. If they match, the script generates a cryptographically secure session identifier. It is this identifier that will be returned from all the subsequent forms and contains enough information for the recieving script to be able to authenticate the user, check that the session has not timed out and ensure that the session identifier has not been tampered with.
The need to provide time limited sessions is important to bear in mind; many common web security mechanisms assume that once authenticated, a user can come back to the server at any time in the future (usually until the browser is restarted). One environment in which the ACORN system is used at Loughborough is with public web browsers and so it was important to use an authentication mechanism that inherently provides support for “timing out” sessions. This is to prevent unscrupulous users from using other people’s account details to gain access to works or to print to printers that they are not themselves entitled to.
Once authenticated, the user is presented with three basic operations that they can perform; they can view the document online, print it out on paper or exit the system. Viewing a document is easily achieved by returning a PDF version of the document. These PDF documents are generated from scanned images by Swets. Many of these PDF documents have actually been OCR’ed from the original scans, as this reduces file size and increases the quality of the on-screen output.
Unfortunately, it has been found that generating OCR’ed PDF is very time consuming, as the current Adobe OCR (Adobe Capture) software often introduces several OCR errors in every page which means that detailed proof reading is required. The volume of documents that even the initial production ACORN service at Loughborough requires has meant that some non-OCRed PDF documents have had to be used. This is worth bearing in mind when attempting to port the system to another site as the Loughborough initial service only covers 24 reading lists from three departments, giving just over 220 articles !
It should be noted that one feature of PDF that the Loughborough implementation of the ACORN system model has made use of is the ability restrict the use of the cut’n’paste and print operations from within the Adobe Acrobat readers. This forces the user to use the print system provided by the ACORN system and therefore permits the printed form of the document to be stamped with the time it was printed and the user it was printed for and also records printing details within the main ACORN database for latter analysis.
Printing within the System
Printing from the ACORN system is somewhat more complicated than simply viewing the document online. When the user elects to print a work, it is the CGI script on the main ACORN server that prepares and submits the print job on the user’s behalf. In the Loughborough implementation of ACORN, the ACORN print system has to be able to deal with both the “standard” Computing Services UNIX and PostScript based print system and also private departmental printers. These latter printers have a restricted set of permitted users and may use Netware or AppleTalk to access their printers and use PCL rather than PostScript as a page description language.
The first stage in the print process is to get the end user to select the printer that they wish to use. They are presented with an HTML form containing a selection list of all the available printers, including both those provided by Computing Services and those handled by the departments’ own systems. The form allows the user to elect to print a range of pages from the article rather than the whole thing and the script also calculates the cost to the end user of printing the whole article on a Computing Services printer (students are currently charged 5p per page for printing to a Computing Services black and white A4 laser printer).
When the user’s choices are returned to the CGI script, the script looks up the printer name in a table on the system that tells it where to locate another file of Perl script that can be used to access that printer. These Perl files are then dynamically “required” into the running CGI script to provide the appropriate interface to the selected printer. The ability of Perl to dynamically bring in and execute new blocks of code at run time is very valuable here, as in some other languages either all printers would have to be included in the CGI program at compile time or another program would need to be forked off to handle the print request. The former option limits the flexibility and modularity of the system and the later increases the resource requirements of the system.
If the user decides to print on a Computing Services printer, the CGI script brings in a standard subroutine that allows it to submit a job to the central campus print server. It then generates a PostScript document from the PDF using the pdftops program from the XPDF distribution [6], and then inserts some more PostScript code into this new document that inserts a light grey username, timestamp and attribution on every page of the document that is printed.
The script then uses a “hacked” version of the normal lpr(1) program (built from the freely available LPRng printing toolkit) that allows the script to actually submit the print job under the end user’s central services username, despite the fact that the script itself is running as an unpriviledged, non-root user on the ACORN server.
If on the other hand the user chooses to print on a departmental printer, the code brought into the CGI script varies depending upon which department and printer is used. The first thing that the code does in these cases does is check whether the user is entitled to use the printer that they have requested. The authenticated username used for access to ACORN as a whole is the basis of this check, though the actual check varies from department to department. For example in one department the end user can print as long as they are a member of the department (which can be deduced from the first two letters of the username) whereas in another, the script has to check with another password file supplied by the department to ensure that the end user has paid a departmental printing subscription.
One departmental printer uses the HP PCL page description language rather than PostScript. In this case, the PDF is converted to PostScript and has the timestamps inserted as described above, and then GhostScript is used to convert the resulting PostScript document in to a PCL file.
This particular printer and some of the other departmental printers are not available via the standard UNIX printing system. This is a problem as the main server machine is a Solaris machine that can only print to a UNIX style print service. To get round this, another machine is used as a multiprotocol printing gateway. This machine is an AMD586-133 based PC with 8MB of memory running Linux 2.0.27. Linux is a free UNIX like operating system that is capable of dealing with UNIX, Netware, SAMBA and AppleTalk style printing using freely available tools.
The Linux box hosts a number of UNIX print queues that can only be seen by the main ACORN server. These queues allow the ACORN CGI script to submit the departmental print jobs using the normal UNIX lpr(1). Each queue has an input filter that takes a print job from the queue, connects to the appropriate remote print server and then submits the job to that print system. As this is a fairly simple task for Linux, a small PC is more than capable of handling it. It is a different matter if the backend script has to do the PostScript to PCL conversion as well as gateway it into the other print system, as was discovered during the implementation. The GhostScript program used to do the conversion can make a fairly heavy demand on the memory of the machine, which would be made worse if more than one print job is underway at once.
For anyone considering implementing the ACORN system model at another site it is worth taking note that dealing with the variety of printing mechanisms that are in use in many Universities can be a bit of a nightmare. Luckily the modular approach taken with the initial implementation at Loughborough allows new printers to be brought online without rewriting the rest of the system. Also once code for one departmental printer is written it is sometimes possible to reuse the basic code for other similarly configured printers.
The ACORN CGI script also records in the main Sybase database who requested the print job, what document was presented and when the job was submitted to the print system. This information can then be used by the librarians and ACORN Project staff for calculating royalties due to publishers, identifying popular works and capacity planning for future use of the system.
Conclusions
This document has attempted to provide a concise overview of the abstract ACORN system model, and also a more detailed explanation of the initial production implementation of an ACORN service based on that model at Loughborough. The ACORN system model is intended to be transportable, so that the basic idea behind the system can be applied at other sites.
It may be that some parts of the Loughborough implementation will be useful as they stand at other sites. For example, some interest has already been expressed in the CLEAR database implementation by other libraries. Other elements are obviously very much depended on the existing local infrastructure in use. The print system is the classic example of this, but as has been seen other parts of the Loughborough implementation such as the Talis style WORK_ID’s may require altering to fit in with local needs at other sites.
In order to test how transportable the ACORN system model really is, there are plans to investigate the ease with which the ACORN system can be implemented at Leicester University. This system will be working in a different library environment, with different printing systems available and possibly with a different main database package. This will demonstrate both whether the ACORN system model can fit in with the needs of different libraries and also which parts of the implementation of the system can be “packaged” and which need to be rewritten for each installation.
The initial production implementation of the ACORN system at Loughborough is currently in use by students studying a variety of modules hosted by the departments of Geography, Human Sciences and Information and Library Studies. Initial reactions seem fairly positive and, aside from some teething problems with the PostScript to PCL conversions for departmental printing, it seems to be operating fairly smoothly.
References
[1] ACORN Project Web site,
http://acorn.lboro.ac.uk/
[2] eLib Programme Web site,
http://www.ukoln.ac.uk/elib/
[3] Loughborough University Web site,
http://www.lboro.ac.uk/
[4] Swets & Zeitlinger b.v. Web site,
http://www.swets.nl/
[5] Leicester University Web site,
http://www.leicester.ac.uk/
[6] Derek B. Noonburg XPDF distribution,
http://www.contrib.andrew.cmu.edu/usr/dn0o/xpdf/xpdf.html
Author Details
Jon KnightROADS Technical Developer
Email: jon@net.lut.ac.uk
Own Web Site: http://www.roads.lut.ac.uk/People/jon.html
Tel: +44 1509 228237
Richard Goodman
ACORN Project Technical Officer
Email: R.Goodman@lboro.ac.uk