Dublin Core Management
The Dublin Core Metadata Element Set (the Dublin Core) [1] is a 15 element metadata set that is primarily intended to aid resource discovery on the Web. The elements in the Dublin Core are TITLE, SUBJECT, DESCRIPTION, CREATOR, PUBLISHER, CONTRIBUTOR, DATE, TYPE, FORMAT, IDENTIFIER, SOURCE, LANGUAGE, RELATION, COVERAGE and RIGHTS. As we begin to consider some initial implementations using the Dublin Core we need to consider how best to manage large amounts of metadata across a Web-site. The ways in which we manage Dublin Core metadata need to be able to cope with potential syntax changes in the way that elements are embedded into HTML and allow for the migration of metadata to other formats [2], for example future versions of PICS labels.
Summaries of the current state of the Dublin Core are available elsewhere [3]. In short, the element set is now stable and the ways in which Dublin Core records can be embedded into HTML Web pages are fairly widely agreed. There is still some discussion about the use of some of the elements, however Dublin Core is beginning to be used in several projects [4].
This article is concerned primarily with the practical issues of using Dublin Core metadata to describe Internet resources. It will concentrate on embedding Dublin Core into HTML Web pages with a view to what can be done now - and how can it be done. Three areas need to be considered:
- Syntax issues - how Dublin Core is embedded in HTML.
- Content issues - what sort of data goes into Dublin Core elements.
- Management issues - how can we manage metadata across a Web-site.
Of these, a brief overview, primarily by example, of the syntax for embedding Dublin Core elements into HTML is given here. The second area is barely touched on. The third area forms the bulk of this article - three models for the management of metadata across a Web-site are outlined and the tools that UKOLN are beginning to use to embed metadata into Web pages are described in some detail.
Syntax Issues
By and large the syntax for embedding simple Dublin Core records into HTML Web pages is now agreed, each element name and value being held in a HTML META tag. Unfortunately there are two formats for embedding more complex, ‘qualified’ (see below) Dublin Core elements into HTML, one which is legal in HTML 3.2 (and older versions) and one which will be legal in HTML 4.0 [5].
Firstly, here is a simple example:
<HTML>
<HEAD>
<TITLE>UKOLN: UK Office for Library and Information Networking </TITLE>
<META NAME=“DC.title” CONTENT=“UKOLN: UK Office for Library and Information Networking”>
<META NAME=“DC.subject” CONTENT=“national centre, network information support, library community, awareness, research, information services, public library networking, bibliographic management, distributed library systems, metadata, resource discovery, conferences, lectures, workshops”>
<META NAME=“DC.description” CONTENT=“UKOLN is a national centre for support in network information management in the library and information communities. It provides awareness, research and information services”>
<META NAME=“DC.creator” CONTENT=“UKOLN Information Services Group”>
</HEAD>
<BODY>
…
</BODY>
</HTML>
(The examples given here are largely taken from the UKOLN home page [6]. If you want to see some embedded Dublin Core metadata for real, browse to the page and use your browser’s ‘View source’ option to look at the HTML source of the page).
Note that the META tags are placed within the HEAD section of the page and that the Dublin Core element names are preceded by ‘DC.’ to form the META tag name. By convention the ‘DC’ is uppercase and the element name is lowercase.
Only 4 of the Dublin Core elements are shown in the above example - that’s fine by the way, with the Dublin Core all elements are optional and, as we’ll see in a while, all elements are repeatable. If we consider the Dublin Core elements in this example:
- DC.title is the title of the resource. Note that the normal HTML <TITLE> tag also exists - the issue of the relationship between embedded Dublin Core and other metadata in Web pages will be returned to later on
- DC.subject is by default an unconstrained list of keywords
- DC.description is a short description - short means three or four lines of text typically. Note that in HTML, the META tag CONTENT attribute can be split across several lines in the source file
- DC.creator is the person or organisation primarily responsible for the intellectual content of the work.
Refining Dublin Core element meanings
The meaning of Dublin Core elements can be refined using three ‘qualifiers’ - LANGUAGE, SCHEME and TYPE.
The LANGUAGE qualifier specifies the language used in the element value (not the language of the resource itself, that’s given in the LANGUAGE element!). The LANGUAGE qualifier will not be described in any detail here.
The SCHEME qualifier specifies a context for the interpretation of a given element. Typically this will be a reference to an externally-defined scheme or accepted standard. For example, if we were to allocate Library of Congress Subject Headings to the UKOLN Web-site we might add:
<META NAME=“DC.subject” CONTENT=“(SCHEME=LCSH) Library information networks – Great Britain”>
<META NAME=“DC.subject” CONTENT=“(SCHEME=LCSH) Information technology – higher education”>
to the META tags above. Note that the SCHEME qualifier is currently embedded into the META tag CONTENT. In HTML 4.0 the META tag will have a separate SCHEME attribute and it will be possible to write:
<META NAME=“DC.subject” SCHEME=“LCSH” CONTENT=“Library information networks – Great Britain”>
<META NAME=“DC.subject” SCHEME=“LCSH” CONTENT=” Information technology – higher education”>
However, this syntax is illegal in HTML 3.2 (or older) and although it is unlikely to cause any serious problems for current Web browsers it would cause the page to fail to validate using an HTML 3.2 based validation service.
Finally, the TYPE qualifier modifies the element name so as to narrow it’s semantics. For example, an author’s email address can be thought of as a sub-element of the CREATOR element. To embed the author’s email address into an HTML page we can write:
<META NAME=“DC.creator.email” CONTENT=“isg@ukoln.ac.uk”>
Repeated elements
Some elements may need to be given several times, in a Web page with more than one author for example. Remember that Dublin Core allows elements to be repeated, so simply repeat the DC.creator META tag several times:
<META name=“DC.creator” content=“Powell, Andy”>
<META name=“DC.creator” content=“Stark, Isobel”>
Note that it is not possible to group Dublin Core elements embedded in HTML in any formal way. So there is no mechanism for grouping pairs of DC.creator and DC.creator.email META tags.
Content Issues
This area is not considered in any detail by this article. In designing a system for managing metadata across a Web-site some non-technical issues will have to be addressed. Selecting the terms used in keyword lists and deciding on a format for names and email addresses for example. One also needs to consider issues of granularity. Which resources should be described? In particular, for a multiple-page document does metadata go into every page or just the title page? One view is that the Dublin Core is primarily being embedded to aid resource discovery so embed it in those resources that you want people to find. In many cases that means that it is only necessary to embed Dublin Core into ‘main’ page (the ‘title’ pages of documents for example). In some cases it will be sensible to embed Dublin Core into all the component pages of a Web resource.
Management Issues
This section presents three models for the way in which Dublin Core metadata can be created and managed across a Web-site; firstly the use of HTML authoring tools to embed Dublin Core directly into an HTML page, secondly the use of Web-site management tools to manage metadata in parallel with HTML pages and lastly the use of Server-Side Includes to embed externally held metadata into an HTML page on-the-fly as the page is served.
HTML Authoring tools
Metadata embedded when resource is created
The first model is to embed the metadata directly into HTML Web pages by hand using whatever HTML editing tools are already in use. In some ways this is a nice simple solution but…
- some HTML authoring tools do their best to hide HTML tags from you and as HTML becomes more complex this is increasingly likely to happen. Simply typing in META tags or cutting and pasting them into your document from elsewhere may not always be possible
- maintaining large numbers of resources with embedded META tags is likely to become problematical if the syntax changes
- finally there is always the potential for META tags being created wrongly, either being syntactically incorrect or using element values in an uncontrolled way.
However this approach does have some advantages. In particular it may be useful for training and raising awareness about the use of META tags.
Web-site management tools
Metadata embedded when resource is published
The second model is to make use of Web-site management tools to manage metadata. These tools have only become available relatively recently and aim to aid the management of whole Web-sites rather than of individual documents. They usually combine editors, for creating Web pages, with other tools for managing those pages across a site. Typically they work by holding all the data for a site in a database. A ‘publish’ button is used to create HTML pages based on the information held in the database. These tools are unlikely to be Dublin Core aware but they are likely to support macros which may allow for the creation of embedded Dublin Core META tags as part of the publishing procedure.
However, it is worth bearing in mind that the formats used to hold data and metadata in the database are likely to be proprietary and there are unlikely to be interchange formats to allow the data to be moved easily into other formats so you need to beware of becoming locked into a single system with this model. Nevertheless, in the longer term this looks likely to be the sensible way to go, not least because of the general advantages for Web-site management that these tools offer. For the moment though it is probably too early to make recommendations about their use, particularly as far as metadata management is concerned.
Embedding On-the-fly
Metadata embedded when resource is served
The third model is to hold the metadata in a separate neutral format and to embed it on-the-fly using Server Side Include (SSI) [7] scripts.
SSIs are a simple mechanism for creating all or part of a Web page dynamically. The Web used to consist of two kinds of pages. Static pages maintained using HTML editors of some kind and dynamic pages generated by CGI scripts. More recently SSIs have allowed static pages to embed other pages or call external scripts to form a part of their content. SSIs are typically used to embed a standard copyright notice into or wrap standard headers and footers around all the pages on a site.
The third model makes use of a SSI script to embed Dublin Core metadata into the page on-the-fly. A potential problem may be performance because, for each page that is served, the Web server has to check the HTML file for a SSI and, if necessary, run a script. However, given that SSIs are increasingly being used for other purposes, this may be a problem that has to be addressed anyway.
One other potential problem is that dynamically generated pages tend to be marked with an expiry date of now, which means that Web caches do not cache them! However, some Web servers, for example Apache, can be configured to give pages containing a SSI a sensible expiry date.
With this model there needs to be a tool for creating metadata in the chosen format. In some cases it may be possible to use a commercially available tool. Alternatively it is possible to use a Web based tool like DC-dot (see below).
Finally, this model needs a mechanism for associating the resource with it’s metadata. There are two possibilities here. The two could be tied together using a simple filename based mapping from the HTML file to the metadata file. Alternatively, one could assign some sort of unique identifier, for example a PURL or a DOI, to each page and then use that to identify the metadata file.
DC-dot
DC-dot [8] is a Web based tool for creating Dublin Core HTML META tags. The use of tools such as this may be the simplest way of creating the metadata to be embedded using either the first or third models above.
DC-dot works by first prompting for the URL of the resource that you want to describe. It will then retrieve the page from the Web and automatically generate some Dublin Core META tags based either on existing metadata in the page (title, keywords, description and existing Dublin Core) or on the contents of the page. It should be noted that the methods used to automatically generate metadata are nothing to write home about and typically generate tags that need further modification by the user. DC-dot also looks at the domain name of the Web-site and uses that to determine the publisher - sometimes this produces sensible results, sometimes not!
DC-dot allows you to edit and extend the automatically generated tags. Having done so, you can either cut-and-paste the resulting tags into your HTML page source or save the metadata in a variety of alternate formats including USMARC records, SOIF records, ROADS/WHOIS++ templates and GILS records.
DC-dot can either be accessed from the UKOLN Web-site or download and run locally - see the UKOLN metadata software tools page for details [9].
The Metadata system at UKOLN
At UKOLN we are beginning to embed Dublin Core metadata into our Web pages. Initially we are concentrating on Ariadne articles because we have a requirement to embed metadata for collection by the NewsAgent Web robot into Ariadne as part of our role in the NewsAgent for Libraries [10] eLib project.
Currently our plans are to:
- Store metadata using SOIF records
- Embed on-the-fly using an Apache SSI script [11]
- Use MS-Access as tool to create the records
- Associate metadata with resource by co-locating them in the Web server filestore
SOIF (the Summary Object Interchange Format [12]) is the format used by Harvest [13] and the Netscape Catalogue Server. In some ways SOIF is not an ideal format for holding Dublin Core metadata but it is fairly widely understood and relatively simple to work with. SOIF records have a simple attribute/value pair syntax, however the format used is not significant for this discussion and the details of SOIF will not be described here. The use of an XML based format to hold the Dublin Core records would be a sensible alternative.
SOIF records could be created using the DC-dot Web based tool described above. At UKOLN, after some experimentation with various tools, we have decided to use an MS-Access database to create our Dublin Core records. This integrates quite nicely with the other tools in use on UKOLN staff PCs. Finally we have decided to associate a resource with it’s metadata by placing them in separate files in the same directory on the Web server, with the name of the SOIF file being derived from the name of the HTML file.
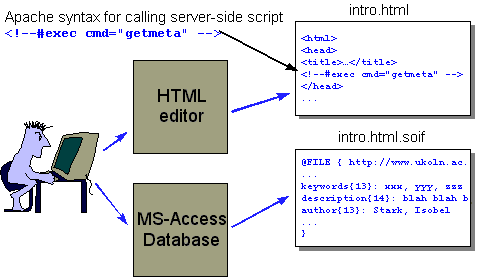
The diagram should give you an idea of the way things work. Consider a UKOLN author creating a Web page. Having edited the page they then use the MS-Access database to create a SOIF record describing it. The SOIF record is placed in the same directory as the HTML file, using the filename with a ‘.soif’ suffix. For example, the description for intro.html is put into intro.html.soif.
Each Web page for which metadata is created must have a single line added to it. This is the line that calls the SSI script. The example in the diagram above shows the syntax for calling SSIs used by Apache.
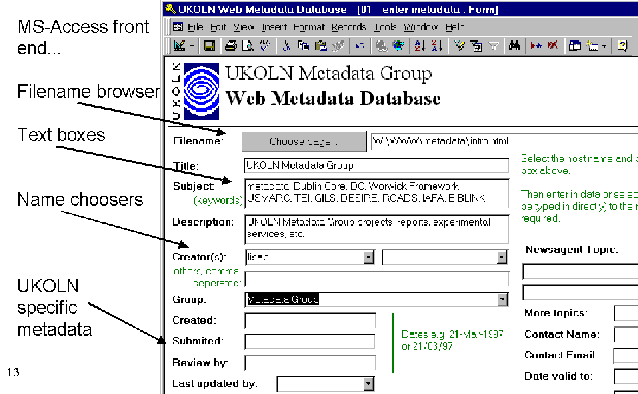
Initially the person creating the metadata browses to the file we are describing. By using an ActiveX Control the browsing can be done using a Web browser embedded into MS-Access. Having found the required page, the person enters various metadata items - title, keywords, description, etc. As the record is saved a small Visual Basic program writes out a SOIF record as well. It is important to remember that with this system, MS-Access is simply being used as a front-end tool.
Note that this system allows us to create some NewsAgent specific metadata which will be harvested by the NewsAgent robot and some UKOLN specific metadata which will be used for Web-site management purposes. For example a group ownership is assigned to each page which will allow us to locate all the pages owned by a particular UKOLN group in the future. Currently it is envisaged that the UKOLN specific metadata will be stored in the SOIF records but will not be embedded into Web pages.
Now, lets look at how things work from the point of a Web robot.
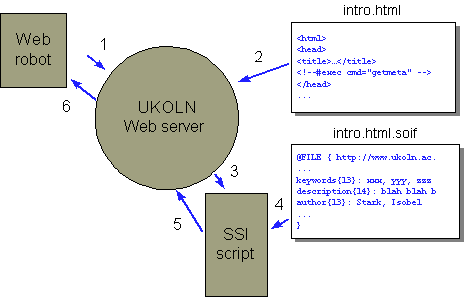
Imagine a robot collecting a page from the UKOLN web site. It sends a request for the page to the UKOLN Web server(1). Normally all the server has to do is read the file from disk and send it back to the robot. In our case however, the server must also parse the file looking for SSIs (2). If it finds one, it calls the SSI script (3). One of the pieces of information that the Web server passes to the script is the name of the file it is currently reading. The script appends ‘.soif’ to the filename. If the resulting filename exists, it reads the SOIF record (4), converts it to HTML META tags and passes them back to the server (5). The Web server adds the META tags to the page and returns the whole thing to the robot (6).
Remember that, as far as the UKOLN Web server is concerned, a robot is no different to a person browsing the Web so this procedure is followed for each and every access to the page. However, in theory, it might be possible for the script to check who is accessing the page and only generate Dublin Core META tags for those robots known to make use of them.
Dublin Core vs. Alta Vista style
tags Many pages on the Web already have metadata embedded in them. Most pages, for example, have an HTML <TITLE> tag - because without it they are not conformant HTML pages. Some pages also have KEYWORDS and DESCRIPTION META tags because these are used by the big search engines such as Alta Vista. Note that none of the big search engines, as far as I’m aware, look for Dublin Core META tags yet! That’s not to say that they won’t index the words found in Dublin Core META tags, but they don’t currently give those words any special significance.
Given that we have a script generating our DC.subject and DC.description META tags it seems sensible to let it generate keywords and description META tags containing the same values. So we might end up with:
<META NAME=“DC.subject” CONTENT=“national centre, network information support, library community, awareness, research, information services, public library networking, bibliographic management, distributed library systems, metadata, resource discovery, conferences, lectures, workshops”>
<META NAME=“DC.description” CONTENT=“UKOLN is a national centre for support in network information management in the library and information communities. It provides awareness, research and information services”>
<META NAME=“keywords” CONTENT=“national centre, network information support, library community, awareness, research, information services, public library networking, bibliographic management, distributed library systems, metadata, resource discovery, conferences, lectures, workshops”>
<META NAME=“description” CONTENT=“UKOLN is a national centre for support in network information management in the library and information communities. It provides awareness, research and information services”>
It is not so clear whether the DC.title META tag and <TITLE> tag should be the same. Currently at UKOLN, we expect that the <TITLE> tag will continue to be embedded into the Web page by the person creating the page and that the DC.title META tag will be held in the SOIF record and embedded on-the-fly by the SSI script.
Conclusions
This article proposed three areas that should be considered by those thinking about using the Dublin Core to describe the resources on their Web-site. It concentrated primarily on the issues surrounding how best to manage such metadata. By beginning to implement systems for managing metadata we can get some experience of real use and build up a body of resources with embedded Dublin Core. It looked at three models for the way in which metadata can be managed, highlighting the key issues of each. The issues of long term maintenance and transition to other formats should not be underestimated. It also described in some detail one particular implementation of one of these models that is beginning to be used at UKOLN. It is acknowledged that the design of this implementation is not perfect and may well change as we begin to work with significant amounts of metadata.
References
[1] The Dublin Core Metadata Element Set,
http://purl.org/metadata/dublin_core
[2] Web Developments Related to Metadata,
http://www.ukoln.ac.uk/groups/web-focus/events/seminars/metadata-june1997/iap-html/
[3] The 4th Dublin Core Metadata Workshop Report,
http://hosted.ukoln.ac.uk/mirrored/lis-journals/dlib/dlib/dlib/june97/metadata/06weibel.html
[4] UKOLN Metadata Resources - Dublin Core,
http://www.ukoln.ac.uk/metadata/resources/dc.html
[5] HTML 4.0 W3C Working Draft,
http://www.w3.org/TR/WD-html40-970708/
[6] UKOLN Home page,
http://www.ukoln.ac.uk/
[7] Using Server Side Includes Apache Week issue 27,
http://www.apacheweek.com/features/ssi
[8] DC-dot - a Dublin Core META tag creator,
http://www.ukoln.ac.uk/metadata/dcdot/
[9] UKOLN metadata software tools,
http://www.ukoln.ac.uk/metadata/software-tools/
[10] NewsAgent for Libraries,
http://www.sbu.ac.uk/~litc/newsagent/
[11] soif2metadc Perl script,
http://www.ukoln.ac.uk/metadata/software-tools/#soif2metadc/
[12] Summary Object Interchange Format (SOIF) - A review of metadata: a survey of current resource description formats
http://www.ukoln.ac.uk/metadata/DESIRE/overview/rev_20.htm
[13] Harvest Web Indexing
http://www.tardis.ed.ac.uk/harvest/
Author details
Andy Powell,Technical Development and Research,
UKOLN
Email: a.powell@ukoln.ac.uk