VERITY
Abstract
The majority of library enquiry systems usually consist of a non-graphical interface linked to a library catalogue (Online Public Access Catalog, or OPAC). Graphics, animation and sound are usually sacrificed to speed up the enquiry process. Some interfaces support the Hypertext Transfer Protocol (http) and can therefore be accessed on the World Wide Web (Web). Although they allow access using a number of keywords (author, subject, title, etc.), they do not provide any help on how the catalogues are accessed, how to structure or refine a query or how to evaluate the responses. To add to the confusion, there are many different manufacturers of OPACs. Information Services at the University of Sunderland is currently developing an intelligent enquiry system that uses an interactive dialogue process to direct the user to information. The system also includes a skills component based on the learning dialogue explaining the information seeking process, and finally a referral service that forwards unanswered queries to a transnational mediated special interest group (SIG).
Definition
Verity is exploring new ways of providing virtual library services that are creative, stimulating and educational for young people in the 13-19 age group. The aim is to design a system that helps those users with their information enquiries, in a context that encourages the development and understanding of their own information seeking skills. Verity will teach young people to find and manage information held in libraries and on electronic networks. Verity can be browsed through any (fairly recent) Web browser (Netscape, Internet Explorer).
One of Verity’s key challenges is the fact that it’s being developed as a multilingual application, and developed in parallel by five partners, the lead partner based in the UK and other partners in Finland, Germany, Greece and Portugal [1].
Why Verity?
Web-based query engines may well know about library catalogues which manage to appear on the Web, but they cannot actually directly query those catalogues - they can only point the user at them. The user then has to go off and learn which library to query, and how exactly to go about doing that, and then evaluate the results [2].
Verity demonstrates that the keywords behind a given library catalogue can be made available on the Web to be queried and accessed by a third-party enquiry engine (rather than the enquiry mechanism of that particular catalogue).
Verity doesn’t have to maintain such databases itself, it simply has to know about and be allowed to access those databases (or at least part(s) of them) that librarians and OPACs currently maintain as part of their own work. After all, more and more academic libraries are placing their catalogues on the World Wide Web [3][4].
Scope of Verity
There are many issues that Verity can actively tackle: the age range is significant in the design of Verity, not just as an issue of attractiveness but in terms of the resources it encourages young people to use. The resources have to be relevant to their concerns, their educational imperatives, and address issues such as general suitability.
Any integration of a facility like Verity into school or college will encourage young people to find information, integrate higher-resourced or more traditionally research-based libraries into lower-resourced public and school libraries, and will also augment the role and standing of librarians and information providers. The trend of libraries and information provision over the past five years has been towards better access at lower cost [5].
However, unless young people are skilled enough to find and incorporate the growing corpus of knowledge much of it will pass them by. Verity has an integrated “Information Skills” component that will actively guide the user through a query and will furnish a set of results tailored to that user. This is a trend already seen in search services [6][7], but Verity will include such an aspect as an integral interactive component of its service. It will also incorporate a much more proactive approach towards developing the user’s skills.
The precise methodology to achieve such integration is described in Section 2.0, and Section 3.0 then looks more specifically at the particular challenges associated with offering a multilingual service. Section 4.0 builds on those general technical and multilingual parameters in order to address specifically the protocols within which Verity must work.
Methodology
The development life cycle process of Verity follows the same traditional route as most software engineering projects. The initial investigations into the technical aspects suggested that the best way to develop and communicate the ideas inherent in Verity is to create a model of Verity’s components. The first step was to assemble a methodology that would cover areas such as: parallel development of Verity’s components, in-house development, commercial software packages, and protocols.
The project ‘borrowed’ several diagrammatic notations from well established methodologies including IDEF:0 [8] and SSADM [9] as well as ideas and guidelines from general software engineering techniques. The result was a methodology comprising five phases.
Context Diagram
Context diagrams reveal the relationships of Verity vis-a-vis its own main components as well as its external links - for example dependencies on entities such as the Internet or OPACs. We treated Verity as a system with links and dependencies on other autonomous entities (systems that exist without Verity) in order to clarify the type of input to those entities and the type of output Verity expects.
We identified 4 major verity components: Information Skills, Enquiry, Referral and the so-called “Fourth Element” (a category which subsumes the necessary technology and software to make Verity work). Data Flow Diagrams (DFD’s)
These diagrams proved to be the best way of modelling each Verity component and at the same time distinguish between processes, states and storage. The diagrams helped identify the links between each modelled component and the rest of Verity.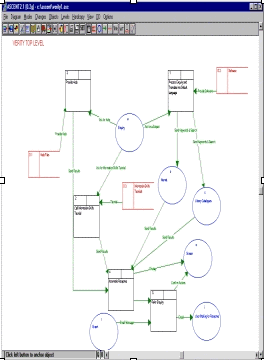
Figure 1. Verity Architecture
The approach was carried out for each of the 4 major components. The end product was a list of activities, processes and storage. Activities refer to the code or the algorithms we need to build in order to carry out the processes described in the DFD. Storage boxes identified the needs of the system in terms of databases and files.
Entity Relationship Diagrams [10]
The modelling proposal described in the previous paragraphs takes an information flow viewpoint of Verity. For each one of the components, sub-components, activities and processes we need to identify the set of resources that will be allocated to them.
Such a diagram presents the physical view of the system. In other words, the aim is to identify the software tools we need (languages, packages), databases, protocols.
Software Engineering
The final phase of the methodology was to refine the databases and algorithms into their components using normalisation and pseudo-coding respectively.
Dictionary
The dictionary should contain and explain all the technical terms used throughout the modelling process. This is the modelling dictionary, not to be confused with Verity’s own dictionaries to handle multilingual input.
Technical Requirements
An early step was to assess the language implications of the project. According to the initial requirements, the system is required to accept a query about a subject in a natural language format, identify the language (English, Finnish, German, Greek, Portuguese), translate the query from any of the five languages into English keywords (default or target language), then extract those words that could be used as keywords to retrieve information from the Verity database, and finally display the findings on the screen.
That is, the process identifies words that can be used as keywords - usually nouns with some verbs and adjectives. When all these words have been identified, they need to be translated to an appropriate default language (in our case, English).
Dictionaries contain only the root of each word or its basic form when it has to do with verbs. However, natural language queries will probably contain words in various forms and tenses. In order to extract the root word, each word has to go through the process of stemming. Both processes are described below.
Morphological Analysers
Morphological analysers are software tools used to assist the process of identifying and extracting only these words in the query that can be used to retrieve information from a database. During the process of tagging, each word of the query will be identified according to its function (e.g. noun) and then tagged:
| Word in the query | “find” |
| Word after Tagging | (Verb “find”) |
| Word in the query | “cat” |
| Word after Tagging | (Noun “cat”) |
Queries in a natural language form will certainly contain word in many forms i.e. nouns in plural, verbs in their past tense etc. Stemming is the process of identifying the root of each word of the query and returning that word:
| Word in the query | “was” |
| Word after stemming | (“be+ed”) |
| Word in the query | “sitting” |
| Word after stemming | (“sit+ing”) |
Systems Architecture
Figure 2 illustrates the systems architecture. The system is currently being developed on a Windows NT server for Widows 95 clients.
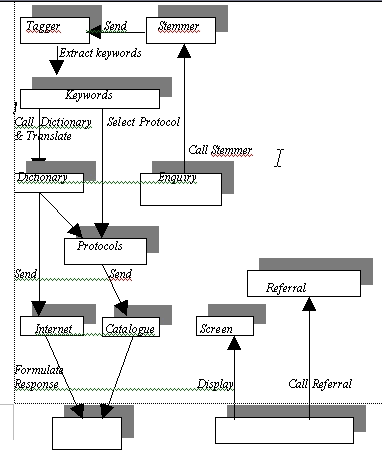
Figure 2. Query Processing
Architecture Figure 2 shows the main processes that lead to the extraction of keywords before they are sent to the Internet, OPACs, or other resources.
Protocols
Library catalogues are software specific, but generally most OPACs in libraries display the familiar command line “Telnet-like” interface. For some time there has been a client/server (or “origin/target”) based Z39.50 [11] standard allowing the user of, say, a Dynix-based library catalogue to also search, say, a Unicorn OPAC. Z39.50 is a standard by which different software products can talk to each other and exchange data. The standard itself, of course, does not provide the user interface, that is up to the individual software house.
Z39.50 and SR (“Search and Retrieve”) are not quite synonymous. Z39.50 can be taken to be a United States implementation, and SR the international standard - in fact, a 1993 subset of the more functional Z39.50. SR developments seem to be focussed mainly in Europe. The two protocols overlap in many areas, and usually SR can ignore or step around the parts of Z39.50 that it doesn’t understand - for example, the British Library structured its development plans during the late 1990’s on the understanding that Z39.50 version 3 would be accepted as SR Version 2 [12].
There are many European and other initiatives to develop Z39.50 integration further (e.g. into the Web) - three examples being the Europagate project, the integration of Z39.50 into LIBERTAS and in the UK the Z39.50/SR Pre-Implementors Group (PIG). In the UK, there is a good body of general information on Z39.50 provided by, amongst others, the UK Office for Library and Information Networking (UKOLN) and by the British Library [11].
The experience in Germany is perhaps indicative of the difficulties of operating full Z39.50 integration: the German DBV-OSI II Project (Open Communication between Library and Information Retrieval Systems) is aimed at removing the present subtle differences between the several regional union catalogues.
A good example of collaboration in the Northern part of Germany is their regional union catalogue based on PICA which involves public libraries. In other regions public libraries have their own catalogue systems. It’s not that regional catalogues are particularly more complicated so far as technology is concerned, the difficulties are more to do with agreements amongst information providers about cataloguing standards (and this even though standardised cataloguing is used in Germany). For these very reasons we think that such difficulties will be of less relevance in the future, when already so many libraries offer Internet (and specifically Web) access to their catalogues.[3][4]
So far as Verity development is concerned, this has encouraged us to decide that links to, say, OPACs can only be to those city and library OPACs which will be accessible via the Internet.
Web Based Protocols
Internet protocols (Telnet, FTP, Mail and the Web protocol http) are well understood and accepted as a standard offering interoperability between platforms, domains and (perhaps most importantly!) age-groups. Verity is not about simply offering an interesting way to search a given family of library catalogues, it also offers the opportunity to search the Web in an integrated and educative way. The idea is that an entire valuable and previously largely inaccessible corpus of quality information (academic and public library collections as well as more specialised library-based CD-ROM collections, or digitised library-based collections) should be made available to young users, at the very least helping them hone their acquisition of learning skills in a very rapidly changing environment.
Future Work
The implementation of the project will be carried out during 1998⁄99. The implementation has been divided into 5 phases including the development of the
Natural Language Query Processing Algorithm
Graphical User Interface
Information Skills Content
Protocols to link Verity with the Web
Protocols to link current Library Catalogues to the Web.
During early 1999 the five Verity partners will develop national models based on the architecture described above. During 1999 and into 2000 the partners will develop and roll out a unified Verity service, capable of being used on the Web or perhaps packaged on a CD for integration in a library’s or a school’s own information provision services.
Conclusions
The aim of the Verity project is to assist users to find information fast and at the same time teach them the information skills required. The system uses an attractive graphical user interface with animations and sounds associated with its options and navigation patterns, and will work through the user’s familiar Web browser. Verity offers a low maintenance way of teaching and guiding users through the process of finding information.
References
- Verity Home Page
http://www.library.sunderland.ac.uk/homepage/verity.htm - Salampasis M Agent Based Hypermedia Digital Library, 1998 Thesis. Sunderland University.
- webCATS
http://www.lights.com/webcats/ - UK-based National Information Services and Systems
http://www.niss.ac.uk/reference/opacs.html - UK-based Electronic Libraries Programme (eLib)
http://www.ukoln.ac.uk/services/elib/ - Ask Jeeves
http://www.askjeeves.com/ - Firefly
http://www.ffly.com:80/ - IDEF Methods
http://www.idef.com/ - Skidmore S., Farmer R., Mills G. SSADM Models and Methods version, Blackwell NCC 1992
- Yourdon E. Object Oriented Analysis and Design: Case Studies, Yourdon Press New Jersey 1994UK-based Electronic Libraries Programme (eLib)
- Z39.50
http://www.ukoln.ac.uk/dlis/z3950/ - Library Information Technology Centre (LITC), Report No 7, Z39.50 and SR
http://www.sbu.ac.uk/~litc/
Other report titles in the series include The World Wide Web in Libraries and Retrospective Conversion and Sources of Bibliographic Record Supply. - Grafenstette, G. (Ed). Cross Language Information Retrieval, Kluwer Academic Publishers 1998.
Author Details
Panayiotis Periorellis and Walter ScalesUniversity of Sunderland, Information Services
Chester Road Library, Sunderland
Email: cs0ppe@isis.sunderland.ac.uk