WebWatch: Conclusions from the WebWatch Project
The WebWatch project [1], which was based at UKOLN, University of Bath and funded the the British Library Research and Innovation Centre (BLRIC), involved the development of robot software to analyse web resources in a variety of (mainly UK) communities. The project analysed several communities and has produced reports on the results. Following the successful completetion of the WebWatch project a final report has been produced. This article summarises the findings published in the report.
Software Development
Following an initial review of robot software tools, it was decided to make use of the Harvest software [2] to analyse web resources. A slightly modified version of the software was used for a number of trawls. However the analysis of the data collected showed that Harvest was limited in its use for analysing (rather than indexing) web resources. Harvest was designed to index the content of HTML pages, whereas we wanted to analyse the HTML tags in HTML pages (and discard the content) and to analyse binary objects, such as images.
Due to the limitations of Harvest, it was decided to develop our own robot tool. The robot was written in Perl and made use of the libwww library.
Trawls
Several trawls were carried out using the WebWatch robot software including:
- UK Public Library Web Sites as described in the LA Record [3]
- UK University Entry Points as described in Ariadne [4]
- eLib Project Pages as described in a report published by UKOLN [5]
- UK Academic Library Web Sites as described in a report published by UKOLN [6]
- A second trawl of UK University Entry Points as described in the Journal of Documentation [7]
- A third trawl of UK University Entry Points as described in a report published by UKOLN [8]
Observations
Rather than repeat the observations from the trawls which have been published elsewhere, this article summarises some of the trends which were observed during the three trawls of UK University entry points.
Trawls of UK University entry points took place on 27 October 1997, 31 July 1998 and 25 November 1998. The first trawl used a list of entry points supplied by NISS [9] but the other two trawls used one supplied by HESA [10]. Slight variations in these two lists, together with incomplete coverage of the entry points (due to errors in the input file and servers being unavilable when the trawl was carried out) means that accurate comparisons cannot be made, although trends can be observed.
Analysis of web server software show that both the Apache and Microsoft IIS servers are growing in popularity, at the expense of the CERN, Netscape and NCSA servers and a number of more specialist servers.
The size of entry points has not changed significantly between the second and third trawls (as mentioned previously, the original version of the WebWatch robot did not allow image files to be analysed, so data of the total size of entry points was not available for the first trawl). Two entry points have grown in size significantly (by over 100 Kb) although one has reduced by 50 Kb).
“Splash screens” are growing in popularity, with a doubling in numbers (from 5 to 10) between October 1997 and November 1998. Splash screens typically use the <META REFRESH=”value” HREF=”url“> HTML element to automatically display the page url after a period of value seconds. Splash screens are often used to display an advertisment (typically containing a large image, before taking the user to the main enty point for a site. Although splash screens can help to advertise an organisation, without forcing users to click to move progress further, they can be counter-productive by slowing down access to the entry points for regular visitors, and, of course, do generate extra network traffic.
Use of Dublin Core Metadata has shown a slight increase, from 2 sites in October 1997 to 11 in November 1998. Use of Dublin Core metadata is still overshadowed by use of “AltaVista” metadata (i.e. <META NAME=“description” CONTENT=“xx”> and <META NAME=“keywords” CONTENT=“xx”>).
A poster which illustrates these trends has been produced, which is shown in Figure 1.
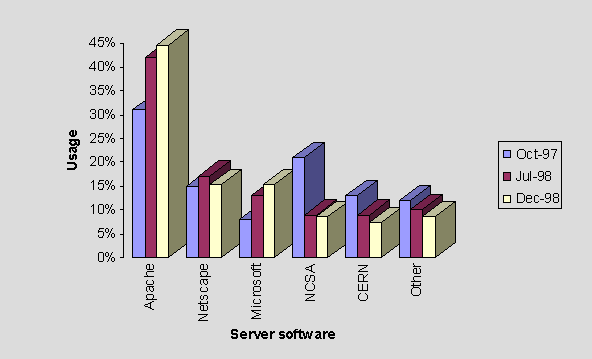
Figure 1: Trends in UK HE Entry Points
WebWatch Web-Based Services
The analyses of the data collected in WebWatch trawls is carried out be a series of Perl scripts and spreadsheet and statistical analysis packages (including Microsoft Excel and SPSS). However it was felt desirable to provide web-based interfaces to a number of the utilities developed by the WebWatch project, so they were available for use by everyone and not just UKOLN staff. Three WebWatch utility programs have been released with a Web interface:
- HTTP-info [11] : which provides details of the HTTP headers for a resource.
- Doc-info [12] : which provides a wide range of information for a web resource, including size details for the resource and embedded objects, details of links from the resource, etc.
- robots.txt Checker [13] : which provides details of the robots.txt file for a given web server.
An illustration of the Doc-info service is shown below.
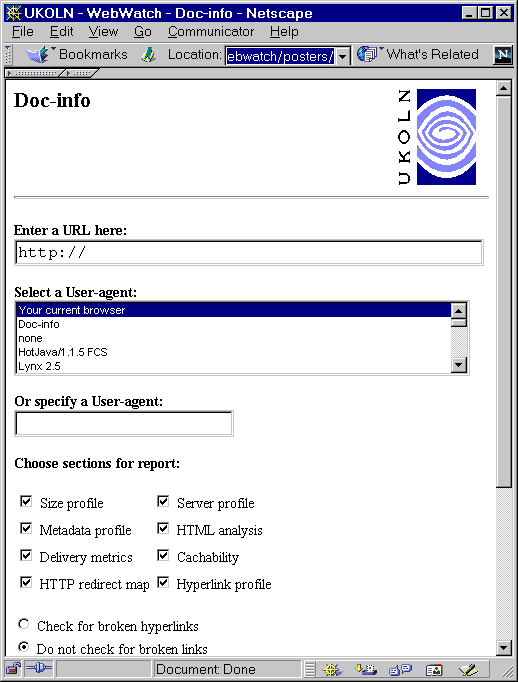 | 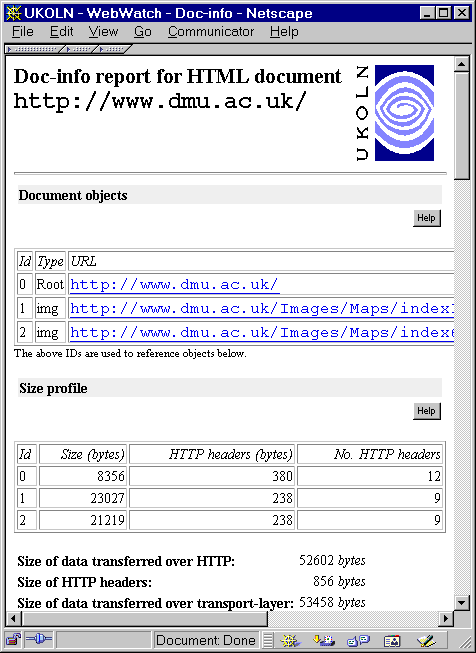 |
| Figure 2a: The Doc-info Service | Figure 2b: Output from the Doc-info Service |
As described elswehere in Ariadne [14] these services can be integrated with a Netscape browser, which makes them much more accessible.
WebWatch Final Report
The final report for the WebWatch project: WebWatching UK Web Communities: The Final WebWatch Report [15] contains more detailed information about the project, including observations from the trawls and relevant recommendations. The report also includes the reports which have been published elsewhere. The report is available in a variety of formats including MS Word, Adobe PDF and HTML.
Thanks
Ian Peacock, who was appointed as the WebWatch Computer Officer on 28 August 1997, left UKOLN to take up a post at Netcraft [16] on 12 February 1999. Netcraft is a commericial organisation which carries out regaular analyses of web sites. Netcraft is based in Bath, so Ian has not had far to move. I would like to take this opportunity to thank Ian for the hard work and dedication he put in to ensuring the success of the WebWatch project.
References
- WebWatch, UKOLN web site
<URL: http://www.ukoln.ac.uk/web-focus/webwatch/> - Harvest, web page
<URL: http://harvest.transarc.com/> - Robot Seeks Public Library Websites, LA Record, Dec. 1997 Vol. 99(12)
<URL: http://www.ukoln.ac.uk/web-focus/webwatch/articles/la-record-dec1997/> - WebWatching UK Universities and Colleges, Ariadne, Issue 12
<URL: http://www.ariadne.ac.uk/issue12/web-focus/> - Report of WebWatch Trawl of eLib Web Sites, UKOLN web site
<URL: http://www.ukoln.ac.uk/web-focus/webwatch/reports/elib-nov1997/> - A Survey of UK Academic Library Web Sites, UKOLN web site <URL: http://www.ukoln.ac.uk/web-focus/webwatch/reports/hei-lib-may1998/>
- How Is My Web Community Doing? Monitoring Trends in Web Service provision, Journal of Documentation, Vol. 55, No. 1 Jan 1999
- Third Crawl of UK Academic Entry Points, UKOLN web site
<URL: http://www.ukoln.ac.uk/web-focus/webwatch/reports/hei-nov1998/> - Alphabetically Sorted List of UK HE Campus Information Systems, NISS web site
<URL: http://www.niss.ac.uk/education/hesites/cwis.html> - HESA List of Higher Education Universities and Colleges, HESA web site
<URL: http://www.hesa.ac.uk/hesect/he_inst.htm> - HTTP-info, UKOLN web site
<URL: http://www.ukoln.ac.uk/web-focus/webwatch/services/http-info/> - Doc-info, UKOLN web site
<URL: http://www.ukoln.ac.uk/web-focus/webwatch/services/doc-info/> - robots.txt Checker, UKOLN web site
<URL: http://www.ukoln.ac.uk/web-focus/webwatch/services/robots-txt/> - Web Focus Corner: Extending Your Browser, Ariadne, issue 19
<URL: http://www.ariadne.ac.uk/issue19/web-focus/> - WebWatching UK Web Communities: Final Report for the WebWatch Project, UKOLN web site
<URL: http://www.ukoln.ac.uk/web-focus/webwatch/reports/final/> - Netcraft, web site
<URL: http://www.netcraft.com/>
Author Details
 Brian Kelly
Brian Kelly
UKOLN
University of Bath
Bath
BA2 7AY
Email: b.kelly@ukoln.ac.uk
Brian Kelly is UK Web Focus. He works for UKOLN, which is based at the University of Bath