ZOPE: Swiss Army Knife for the Web?
Motivation
I would be surprised if most people don’t feel a sense of achievement when they author their first Web page. It’s the first thing you ever made which potentially the rest of the world can see. Others learn about your new skill and before you know it you’ve become the departmental webperson and are buried in an avalanche of other people’s content to “put on the Web”.
The chore of document conversion and the burden of information maintenance quickly dispel the euphoria of your first experience of authoring for the Web. You are in an “ongoing Forth Road Bridge painting-type situation” - having worked through the information tree for which you are allegedly responsible, a year has passed, and much of the information needs updating again.
This state of affairs may still describe the Web editions of many university prospectuses. It certainly described that at Bristol. Revised content would arrive from academic departments as e-mails, faxes, bits of paper, annotated versions of the previous year’s entry. This would be re-typed into a monolithic Word document by the Admissions Office which would be in turn passed to the Information Office to be prepared in a desk-top publishing package to be sent for printing. Only after the printed version of the prospectus had been produced (involving a further iteration of checking with academic departments) was the monolithic Word document then reverse-engineered into a set of several hundred manually authored Web pages. Needless to say this all took a long time and was error prone.
Now, thanks to a Web-enabled database, the process as been reversed. The pages of the Web prospectus are created dynamically “on the fly” and reflect the current content of the back-end database. The database is edited via Web forms. When an edition of the paper prospectus is required the entire content of the database is simply dumped to a monolithic “snapshot” file and this is used as the raw material for the paper publishing process. The secret, of course, has been to separate the information content from the design - the exception rather than the rule for manually created Web pages.
FileMakerPro was the Web-enabled database software employed. Although originally low cost and easy to Web-enable (you don’t need any other server software or middleware), under Windows NT it has proved less than robust (various ruses have had to be employed to run it as an NT service and to stop this service hanging every few days).
Somewhat late in the day we have now started to Web-enable our corporate Oracle databases and it now makes sense to look for an alternative middleware solution which will integrate well with this technology (or at least SQL databases) and which might be supported by our service departments generally. There is also a need to identify a technology (or mixture of technologies) that allow us to automate (or at least devolve extensively) the management of relatively unstructured information (conventional databases tend not to be good at this).
Zope - what is it?
Zope (which stands for Z Object Publishing Environment) is an open source Web application platform from Digital Creations. Zope is freely available [1] for both NT and Unix and will interoperate with Web servers such as Apache and IIS. It competes with middleware products such as Cold Fusion, Netscape Application Server, PHP, mod_perl, Frontier and Vignette. Zope is written in Python [2].
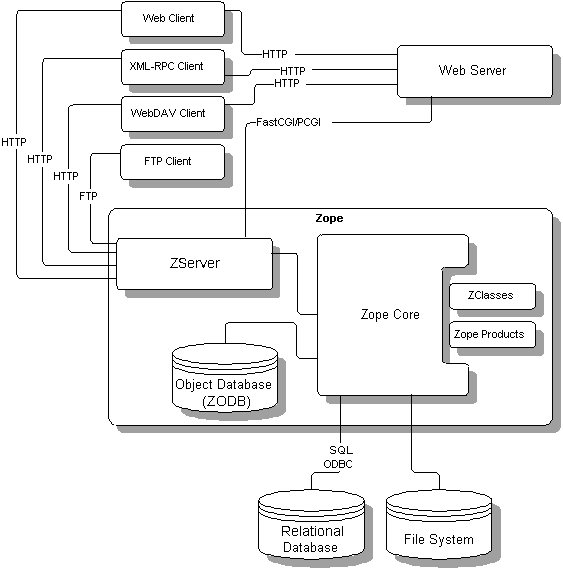
Figure 1: The Zope Architecture [3]
There are many components to the Zope architecture (Fig. 1) and this article will not attempt to cover them all. Instead I will concentrate on those aspects of which I have first hand experience and which should also be regarded (in my view) as key to the efficient running of any Web:
- Transparent publishing
- Devolved content management
- Access to existing data sources
- Integration with existing services
Transparent publishing
If your Web is going to be useful then it must not be just a “read-only” medium for end-users. Publishing information on the Web has to be as easy as word-processing. Zope, via the ZServer component (Fig. 1), offers several publishing mechanisms “straight out of the box”:
- FTP
Any ftp client can upload files into Zope (by default ZServer uses port 8021 rather then 21 so unless you change this you need to configure your ftp client accordingly). Use client software like WS_FTP Pro [4] or Internet Explorer 5 and this publishing method becomes an intuitive drag-and-drop process for the end-user.
- HTTP
Naturally ZServer knows about http (by default it uses port 8080 rather than 80) but it also supports the put method. This means that browsers like Netscape (via Composer) and Amaya [5] can be used to author content - no additional software is required.
- WebDAV
Possibly the most exciting development in this area recently. WebDAV (Distributed Authoring and Versioning) is a protocol [6] providing an extension to HTTP and which brings the concept of “workflow” to the Web. Fully compliant WebDAV clients are thin on the ground at present but for a partial demonstration try Internet Explorer 5 (make sure you install the “Web Folders” option). For those of you who have used Samba [7] to connect to a remote Unix file server the experience will be familiar - drag-and-drop copying of files from your desktop to ZServer.
In fact you don’t copy files to ZServer - this is merely an interface to the Z Object Database (ZODB). Zope is all about objects (which can be files, folders, database connections, program methods, many things) and they all reside in the ZODB (which is in turn one, possibly very large, file in your conventional NT or Unix file system). The cunning thing is that, to an ftp or WebDAV client, the ZODB looks and behaves like a file system.
Devolution of content management
If you wanted you could stop there. The ZServer component gives you a compact and high performance Web-cum-ftp server that is simpler to set up than Apache or IIS. However, it likely that at the very least you will want to be able to create and administer user accounts and folders. This is all done via a Web browser - appending “manage” to any URL brings up an authentication box and, providing you have an appropriate username and password, will take to the management screen (Fig. 2) for that level in the object database hierarchy. (Just as a URL traverses the directories below a “document root” in a conventional file system, the interaction of a URL with the ZODB happens in the same way - with some added magical properties.)
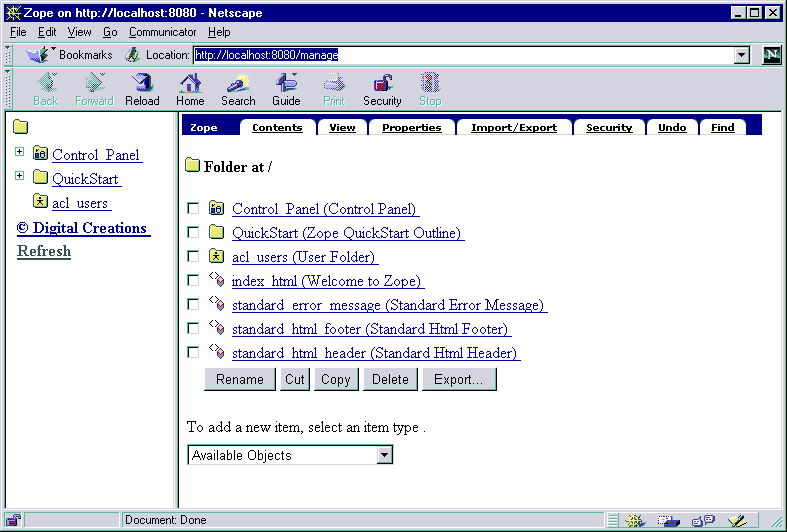
Figure 2: Zope management screen
Zope is based on a business model of “customers who have customers who have customers ….”. The security architecture is nicely explained in the Zope Content Manager’s Guide [8], from which the following account is largely derived. A fundamental idea in Zope security is that administration should be turned over to others as you traverse the folders in a URL. The administrators at each level can define new administrators below their folder, thus passing the work down the hierarchy. To do this effectively, one must understand the four key components of Zope security:
- Users
People (or groups of people) who interact with Zope are represented by Zope “users”, or “user objects”. Zope user objects provide management of authentication information and the kind of access people have.
- Roles
Roles represent kinds of responsibility and authorization, such as “Manager” or “Author.” Roles provide the linkage between authentication and authorization. They are functionally similar to “groups” in other security systems.
- Permissions
Permissions represent like operations on objects and provide an organized mechanism for setting access control on objects. Permissions correspond to the high-level permissions, like “read,” “write,” and “execute,” found in file systems. However, permissions are specific to objects. Different types of objects can provide different, object-specific permissions.
- Acquisition
Acquisition is the mechanism in Zope for sharing information among objects contained in a folder and its subfolders. The Zope security system uses acquisition to share permission settings, so that access can be controlled from high-level folders.
The User Folder object (called “acl_users” in Fig. 2) can be defined in any folder within the hierarchy and is the starting point for managing users. (Note that only a user having a role for which the permission “Add User Folders” is enabled is allowed to do this.) Opening this reveals the User Editing view (Fig. 3) in which user names and passwords can be set, roles allocated and restrictions on access according to IP domain applied. Additional views are available via the Security tab (Figs. 2 and 3) which allow roles and permissions to be modified or added.
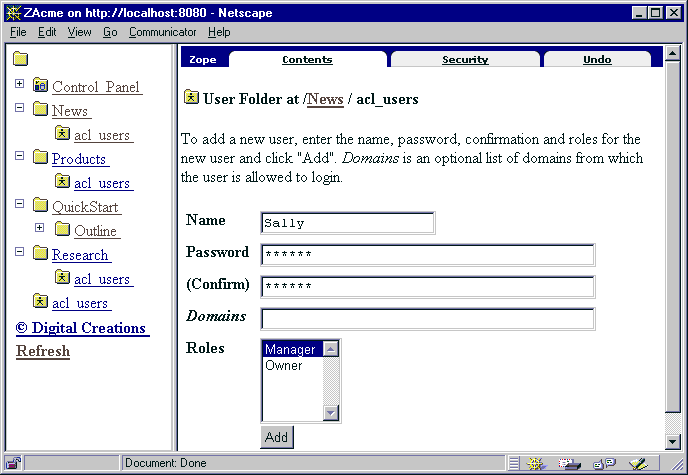
Figure 3: User Editing view
The “user objects” discussed so far are internal to Zope and are based around the http AUTHENTICATED_USER variable. It is possible, however, to create custom User Folders that can be used to interface with external user management systems such as directory servers - see the “Integration with services” section below.
Access to data sources
If you wanted you could stop there. You’ve now replicated a basic Web-cum-ftp server which has a superior security model to Apache or IIS. It is superior because it is finer-grained, based on a hierarchy whose administration can be devolved and which exists entirely within the “sandbox” environment of Zope (it knows nothing about and can’t interact with the security model of the NT or Unix file system that actually hosts Zope). For me, though, stopping here would mean that you missed out on one of the most compelling features of Zope - the ability to integrate with existing data sources.
One of the biggest problems facing organizations (large or small) is the problem of multiple instances of information. A student’s term-time address might be held in the Registry’s student record system, the Library’s management system, the Chemistry department’s Access database, the Hall of Residence’s card index system. No-one knows which one is right, there is no mechanism to synchronise the instances, and the person most affected by the information being wrong (and is arguably the best person to maintain it) can’t help because s/he can’t see any of the instances. The solution, of course, is an information strategy that says “we will only have one instance of information” and a locally supported middleware environment that encourages other organisational units to reference (rather than copy) that instance of information.
For structured information hosted by relational databases Zope achieves this end by another sort of object - the Database Adapter. These come in many flavours [9]. The Gadfly, Oracle, Sybase, Solid and ODBC adapters are supported by Digital Creations. Database adapters contributed by members of the Zope community extend this coverage to include PostgreSQL and MySQL. Note that not all adapters are available for both NT and Unix - in particular ODBC is NT-only and Oracle is Unix-only (though you can connect to Oracle databases from NT via ODBC).
The Gadfly (a simple relational database system implemented in Python and based on SQL) database adapter is the only one available “out of the box” - the others must be downloaded separately and installed as separate “Products”. Installing new products is straightforward under either NT or Unix: stop Zope if it is running, unzip or untar the product into the top-level of your Zope installation, restart Zope and then find the new product under the Available Objects pop-up menu (Fig. 2).
What do you do then? There are essentially three steps and I’ll illustrate them below with screenshots which are restricted to the right-hand frame of the relevant management screen at each stage. In this example I’ll use the ODBC adapter (on NT) to connect to a remote Oracle database (which happens to be running under Solaris) using the standard issue scott/tiger training account and associated employee database (though bear in mind that I could just as easily be accessing the contents of an Excel spreadsheet or Access database hosted by a NT system).
Make the database connection
I add a Z ODBC Database Connection object called “vine” (Fig. 4). The data source “koi” has already been configured via the NT ODBC control panel. The Oracle driver has also been installed and SQLNet configured (i.e. tnsnames.ora has an entry for “koi”).
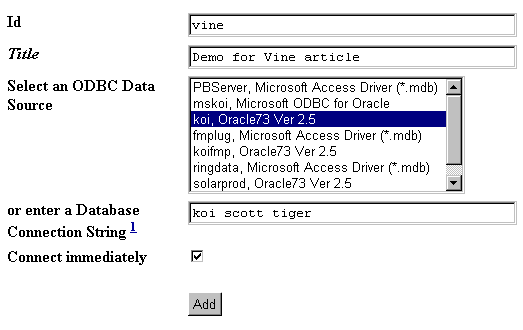
Figure 4: Adding an ODBC Database Connection
Construct a database query
I add an Z SQL Method object (Fig. 5) called “select” which uses the database connection object “vine”. I can interactively test my SQL statement in the management screens. The argument “deptno” is inserted in the query string by using the DTML syntax (see “Some of the bits I’ve missed” section below). The sqltest tag is used to test whether an SQL column is equal to a value given in a DTML variable, in this case “deptno” (the argument and the database column must have the same name).
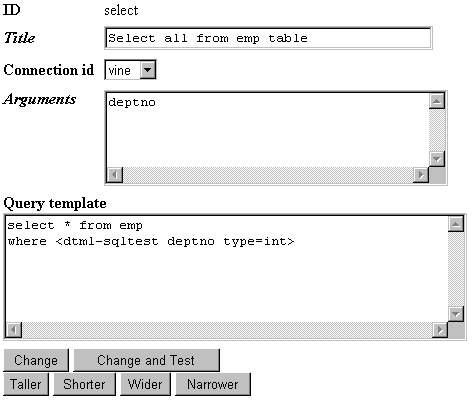
Figure 5: Adding an SQL Method
Build a search interface
Lastly, the Z Search Interface wizard (Fig. 6) helps me build a Web form which I can make available to end-users. The wizard builds two DTML Methods, “report” and “search”, which control the appearance of the Web form and the presentation of the output.
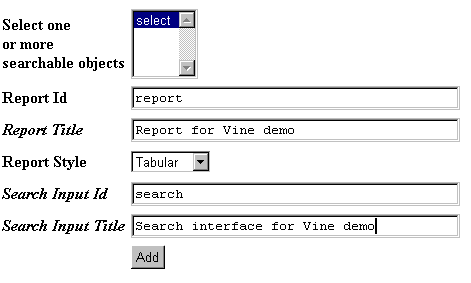
Figure 6: Adding a Search Interface
This takes less than five minutes by which time the management screen for the folder in which these various objects have been created (“vinedemo”) looks like Fig. 7.
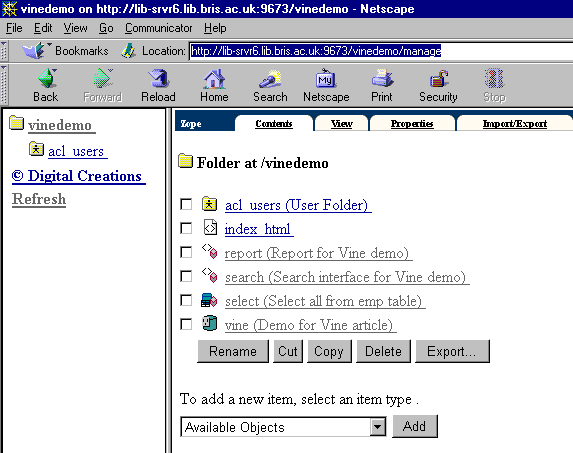
Figure 7: Management view of the vinedemo folder
What does the user who points their browser at the object “search” now see? The Web form and resulting output is given in Fig. 8.

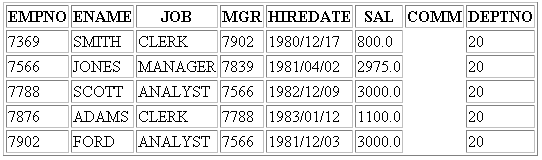
Figure 8: The Web form and resulting report
This is not that pretty. No matter - if you have a modest grasp of HTML you can customize either the “search” (Figs. 9) or “report” (Fig. 10) methods via the Zope management screens. (Figs. 9 & 10 show the default DTML produced by the Z Search Interface wizard.)
<dtml-var standard_html_header>
<form action=“report” method=“get”>
<h2><dtml-var document_title></h2> Enter query parameters:<br>
<table>
<tr><th>Deptno</th>
<td><input name=“deptno”
width=30 value=“”></td></tr>
<tr><td colspan=2 align=center>
<input type=“SUBMIT” name=“SUBMIT” value=“Submit Query”>
</td></tr>
</table>
</form>
<dtml-var standard_html_footer>
Figure 9: The DTML method “search”
<dtml-var standard_html_header>
<dtml-in select size=50 start=query_start>
<dtml-if sequence-start>
<dtml-if previous-sequence>
<a href="<dtml-var URL>
<dtml-var sequence-query>query_start=
<dtml-var previous-sequence-start-number>">
(Previous <dtml-var previous-sequence-size> results)
</a>
</dtml-if previous-sequence>
<table border>
<tr>
<th>EMPNO</th><th>ENAME</th><th>JOB</th><th>MGR</th>
<th>HIREDATE</th><th>SAL</th><th>COMM</th><th>DEPTNO</th>
</tr>
</dtml-if sequence-start>
<tr>
<td><dtml-var EMPNO null=""></td><td><dtml-var ENAME null=""></td>
<td><dtml-var JOB null=""></td><td><dtml-var MGR null=""></td>
<td><dtml-var HIREDATE null=""></td><td><dtml-var SAL null=""></td>
<td><dtml-var COMM null=""></td><td><dtml-var DEPTNO null=""></td>
</tr>
<dtml-if sequence-end>
</table>
<dtml-if next-sequence>
<a href="<dtml-var URL>
<dtml-var sequence-query>query_start=
<dtml-var next-sequence-start-number>">
(Next <dtml-var next-sequence-size> results)
</a> </dtml-if next-sequence>
</dtml-if sequence-end>
<dtml-else>
There was no data matching this <dtml-var title_or_id> query.
</dtml-in>
<dtml-var standard_html_footer>
Figure 10: The DTML method “report”
This rich mix of database adapters clearly provides access to a wide range of “structured” data sources, but what about collections of more loosely structured information like that residing in conventional file systems? No problem - install the Local File System product [10] in to any Zope folder and you will be able to define a “base path” into any level within your local file system. URLs referencing the Zope folder containing the Local File System product can then be simply extended to point to any file or directory sitting below the node in your file system defined by the base path.
Integration with services
If you wanted you could stop there. You’ve essentially replicated what IIS and Active Server Pages or Apache, mod_perl and Perl/DBI (or PHP, or quite a long list of other middleware options) can do (only it takes significantly less time to install and configure Zope). But there’s yet more you can do to integrate the Zope environment with existing (and future) services. (From this point on I’m going beyond the state-of-my-art - but others have made these options work.)
One thing you want to avoid is the overhead of maintaining a separate username/password space that is local to Zope. There are multiple ways of avoiding this via Zope products like etcUserFolder (authenticates against Unix password file), NTUserFolder (NT domain server), LDAPAdapter (LDAP directory service) or MySQL User Folder (passwords held in MySQL database) [11].
Another interesting product is IMAPAdapter giving access to an IMAP mail store. MailHost is a product installed by default which allows you define an SMTP server to be used by the dtml-sendmail tag.
Some of the bits I’ve missed
Document Template Markup Language (DTML) is a facility [12] for generating textual information using a template document and application information stored in Zope. It is used in Zope primarily to generate Hypertext Markup Language (HTML) files, but it can also be used to create other types of textual information. For example, it is used to generate Structured Query Language (SQL) commands in Zope SQL Methods [13]. It used to have a server-side include syntax but now exists in an XML-like form (see Figs. 9 and 10).
I find some aspects of DTML pretty cryptic. Some people say “skip DTML and use Python External Methods instead”. I find Python less cryptic but would be concerned about letting users out of the “sandbox” that is Zope (for the same reasons you don’t give Tom, Dick and Harriet access to your cgi-bin directory). The perfect compromise may have arrived in the shape of Python Methods - a product that allows you to code Python within Zope - apparently some instructors are considering teaching a first course in programming in this way …..
Zope is XML-aware [14] and will export collections of objects in this format. The XML Document product allows you to use XML objects in the Zope environment; you can import or create documents within Zope and format, query, and manipulate XML.
The Confera product gives you the makings of threaded discussion facility though it would require further customisation before it could be used on any sort of scale. Squishdot is a news publishing and discussion product. It creates a place in your Web site where people can post short articles, news items, announcements, etc. as well as hold threaded discussions about them.
Use of the Zope management screens for editing source files quickly becomes a bit tedious (though one can understand the motives for “doing it all in the browser”) and alternatives involving ftp-aware editors are must-haves for anyone contemplating significant development work. Two interesting developments, therefore, are the ZIE (Zope Internet Explorer) project [15] and the Zope Mozilla Initiative [16] which seek to offer within-browser editing of Zope objects (and whole lot more in the case of Mozilla).
Concluding remarks
I still haven’t covered all aspects of Zope - cyber-buzzwords like XML-RPC [17], SOAP [18] and RDF [19] could have been included. Visit www.zope.org for the full story.
I hope this article goes some way to encouraging people to look beyond IIS or Apache. Zope is an alternative to either Web server but it also can be highly complementary (via FastCGI or PersistentCGI, see Fig. 1). You don’t need to know Python to use Zope - but it helps. You don’t need to code DTML - but it also helps. Just a smattering of SQL and a familiarity with HTML will get you a long way (it did for me).
Is the reality as perfect as the article suggests? The main problem is that the hectic pace of development has outpaced the maintenance of documentation. This is not a problem if you’re a Python hacker (“the code is the documentation, man ….”) but can be frustrating if you’re not. Happily there is a vibrant community of users on the Zope mailing list (where I serially lurk to find the answer to everything Zopeish) and many individual and group attempts to write HOW-TOs and the like [20, 21, 22].
A big question with any application server or middleware offering is “Will it scale?”. I don’t think there’s any question over the capacity of Zope to perform as a departmental server - and there are a growing number of impressive and busy Zope-powered sites [23, 24] which are cutting it in the big time Web. Would you bet your “enterprise” on it? Maybe, but perhaps you should have a look at the non-free Zope Enterprise Option (ZEO) alternative first [25].
Zope positively bristles with gadgets to connect to other sources of content and to process content which, in my view, justifies the title of this article. I commend Zope to anyone who wants to work smarter rather than harder with the Web.
References
- http://www.zope.org
- http://www.python.org
- http://www.zope.org/ZopeArchitecture
- http://www.ipswitch.com/Products/WS_FTP
- http://www.w3.org/Amaya/
- http://www.webdav.org/
- http://fi.samba.org/
- http://www.zope.org/Documentation/Guides/ZCMG-HTML/ZCMG.html
- http://www.zope.org/Products
- http://www.zope.org/Members/jfarr/LocalFS
- http://www.zope.org/Products
- http://www.zope.org/Documentation/Guides/DTML-HTML/DTML.html
- http://www.zope.org/Documentation/Guides/ZSQL-HTML/ZSQL.html
- http://www.w3.org/XML/
- http://www.zope.org/Members/johanc/ZIE/ZIE-demo
- http://www.zope.org/Resources/Mozilla/
- http://www.xml.com/pub/2000/01/xmlrpc/index.html
- http://www.digicool.com/News/integrate
- http://www.zope.org/Resources/Mozilla/Projects/RDFSupport/
- http://www.zope.org/Documentation/How-To
- http://weblogs.userland.com/zopeNewbies/
- http://zdp.zope.org/
- http://www.zope.org/Resources/CaseStudies
- http://weblogs.userland.com/zopeNewbies/zopesites/
- http://www.digicool.com/Solutions/ZEOFactSheet.pdf
Acknowledgements
Ann French and Maggie Shapland (University of Bristol), Phil Harris and Joe Nicholls (University of Wales College of Medicine), Tony McDonald (University of Newscastle) and the participants of zope@zope.org.
Updates
- Gain Zope Enlightenment By Grokking Object Orientation
- Boy, I wish this had been around sooner on my Zope voyage. I think I now understand what Classes are for.
- WorldPilot
- The Zope-powered killer application?
- The Jargon Lexicon
- I wasn’t aware (honest) that Perl has been described as a “Swiss Army Chainsaw” when I came up with the title for this article.
- Gadfly
- I might give the impression that the Gadfly database needs to be installed before you can use the Gadfly Database Adapter. This is not the case - as the Z SQL Methods User’s Guide [13] makes clear the the Zope Gadfly product is provided for demonstration purposes. It is only suitable for learning about Zope SQL Methods. Database operations are performed in memory, so it should not be used to create large databases.
- Rewriting the script on app servers
- I found this article quite insightful. An extract:
“If you want a state-of-the-art website then you’ve got two basic choices,” says Vignette’s Pearson. “Option one is you get about 60 per cent of the work done by hiring a slew of programmers, locking them in a room for six months, and hoping for the best. Option two is buying in software which gives you all the basic work plus tools which allow you to customise.”
Option two doesn’t, however, have to be Vignette’s Storyserver (as the earlier bits of the article make clear in discussing the open source options). - Content Management Systems For Linux?
- Leaving aside the question of just what exactly is a CMS, this looks to be an interesting thread comparing many of the candidates. (I hadn’t realised there were problems with mod_perl.)
- ArsDigita Community System
- Funny how you forget stuff. My Web-enabled database journey had an early visit to Philip Greenspun’s excellent but opinionated Philip and Alex’s Guide to Web Publishing but I somehow only re-discovered ACS just recently. Seems to be the only other open-source contender for a Content Management System. It’s very complete in terms of all the off-the-shelf applications that are available.
Author Details
Paul Browning |