Reference Books on the Web
Reference books have been ‘published’ on the web for some years. Several hundred dictionaries are freely available. Many specialist encyclopaedias and subject reference works have been converted to become experimental web services(1).This wave of reference publishing follows no concerted plan. There is no formal market for these services and perhaps there never was an expectation of profit. The early development of the web has been like this. Most of the notable achievements lacked a clear commercial motivation and this has led to the extraordinarily rich and varied choice that the web provides. But unfettered innovation has its downside. Although there are many good reference books on the web, the experimental and haphazard fashion in which they have been launched means that they are not as useful or as ‘findable’ as one might wish. The lack of system is particularly wasteful in the case of reference resources. The web could provide a more useful, reliable and consistent reference service.
The commercial publishers see the potential of web delivery. Several of them have converted their most important reference works into web-based reference services, backed by professional promotion and customer support. There have already been some notable achievements: The Oxford English Dictionary, the Grove Dictionary of Art, and the large reference works published by the Gale Group are pioneers in this gradual mobilisation of reference resources to the worldwide web. So far all the clear-cut commercial successes have been large books, which in their web implementation are offered to subscribers (mainly institutions with libraries) for an annual subscription. But most reference books are much too small, and individually of insufficient value to end-users, to warrant the investment and promotion needed to create a bespoke subscription service for web delivery. The calculation is approximate but a book with a library market value ‘per edition’ of less than $4 million (or a publisher investment in origination of less than $2 million) is unlikely to merit investment in a specific and dedicated web subscription service. A dedicated web service in the reference arena is unlikely to cost less than $500,000 per annum in promotional, technical, administrative and support costs and a publisher will be reluctant to invest a sum of this order with the prospect of annualised subscription revenues from institutions of less than $1 million per annum(2). The overwhelming majority of useful books fail to meet this condition.
What should be done about these smaller reference books (by the standards of Grove and the OED almost every book is a small book)? One way of tackling the problem of the ‘smaller’ books is to develop an aggregation service. Aggregation has worked in creating value and efficient distribution in cognate domains where diverse sources of information need to be collected and served throughout the web. ‘Weather’, ‘news’ and ‘share price’ information are obvious examples of data-types which benefit from centralised aggregation services. There are precedents for aggregating published reference works: Infoplease and Bartleby are both examples of popular consumer-oriented web services pioneering a method of reference aggregation(3). But aggregation on its own may not be enough to create compelling user benefits. Aggregation becomes compelling when the user is able to use a web service to do things which cannot be done with the content in its traditional format: for example the best share price services offer powerful tools for charting share prices and customising these charts. Nothing of the kind can be achieved with the traditional data distribution channels (wire service, teletext or ticker tape).
xrefer is a company specialising in reference works on the web and the founders of xrefer took as their mission the creation of reference services which aggregate and integrate reference works. In the context of reference works aggregation involves bringing diverse works together into a common web site and then providing users with a search engine which executes searches on the complete aggregated library of reference content. Aggregation leads to efficient distribution (users get to know that a collection of reference works can be found at one source) and it also enables ‘power searching’ across a range of titles, but integration would ensure that the whole collection of reference material would contain signposts which relate entries found in disparate sources. A compelling integration strategy would lead to improvements in browsing and navigation. xrefer’s mission was to develop a method which would strengthen the aggregation approach by building a framework of navigation and links that permits smarter browsing,. It was felt that it should be possible in a web environment for a user seamlessly to navigate from an entry in one reference source to an entry in any other source which treats of the same subjects.
Citations, cross-references and xreferences
What is a reference book? We can probably recognise one when we use it, but any definition is messy. Examples of reference works include: dictionaries, phrase books, grammars, thesauri, catalogues, chronologies, encyclopaedia, atlases, gazetteers, travel guides, bibliographies, directories etc. This is a very heterogeneous grouping and it is not easy to see the common factors. We might consider two operational definitions. The ‘cheating’ definition is to say that a reference book is a book that the librarian will put in the reference section of the library, which leaves us with the question ‘What is the reference section?’. The apparently tautologous definition is not completely empty. The point is that librarians and users do treat reference books differently from other books and even in private libraries, reference books are usually grouped together. To classify a book as belonging to a library’s reference section may also mean that the book will not be available for borrowing and is available for the readers to consult while they are in the library. A reference book is the kind of work that a user consults rather than reads from cover to cover. ‘Consults’ is an important word. A reference book is a book a reader will use while reading another book, a book that does not need to be read at a stretch. If we switch modes from the domain of bibliography and volumes printed on paper, a reference service on a network is liable to be needed throughout the network, its use will be episodic and somewhat unpredictable, but it is also liable to warrant centralised management. In network terms, reference works are resources most efficiently deployed on the server side(4). This is a pragmatic and behavioural definition but it is valuable in pointing us to the fact that reference works on the web need to be maintained and may need to be consulted from any context.
A second definition is that a reference work is a book comprising multiple entries that contains a network of ‘cross-references’ as opposed to citations or page references. This is really too narrow a definition because atlases, catalogues and bibliographies are clearly reference works although they may not contain cross-references. At xrefer we like this over-narrow ‘definition’ of reference works, because these are the kinds of reference books (internally cross-referenced or self-referenced) that are particularly amenable to our technology. But an atlas is certainly a reference book and an atlas is not usually cross-referenced (except via a gazetteer or index), so we are left with the point that some reference books have cross-references and others do not. As it happens, reference books also may or may not contain citations. But citations and cross-references are different. What hangs on the distinction between a citation and a cross-reference (or an index entry, or a table of contents)? All of these various literary devices can be rendered as hyperlinks if they are transferred to the web. Citations are most like the classic hyperlink on a web page. Most references in published literature are citations (ie references to a previously published document to which the writer wishes to draw attention), they are typically to works by another author in another publication. The form of a citation enables the reader to determine its target (publication, date, page etc). The typical citation is very like a hyperlink, especially in being a one-way reference to a prior publication(5).
Cross-references as they appear in reference works are different. They are references to the same work and they are unusual in that the form of the cross-reference tells the user what the link is about, as well as enabling her to locate it. It is the inherently ‘semantic’ quality of a cross-reference that makes it possible for xrefer’s system to build navigational links between books. Books may use very different typographic conventions to demarcate the cross reference (‘Wittgenstein*’, ‘the enlightenment’, ‘Higgs boson’) but the user will understand that the reference is to the same book and she will know that the subject or topic of the cross-reference is variously Wittgenstein, the Enlightenment or Higgs bosons. The typical citation has no content, it is all about location, location, location; but a cross-reference in the sense we are interested in has meaning and content. It tells the reader that two entries are linked by a specific topic and that the editor or compiler of the reference work thought it important that the link should be marked. If we look at the body of an entry on Higgs bosons in the Penguin Dictionary of Science (see Figure 1), we can see that the editor of that book, felt that it was relevant to point the reader to related topics ‘boson’, ‘W boson’ ‘Z boson’, ‘weak interaction’, and ‘standard model’. Each entry in a cross-referenced reference work gives a little conceptual map of related concepts, and of course each entry is distinct and different.
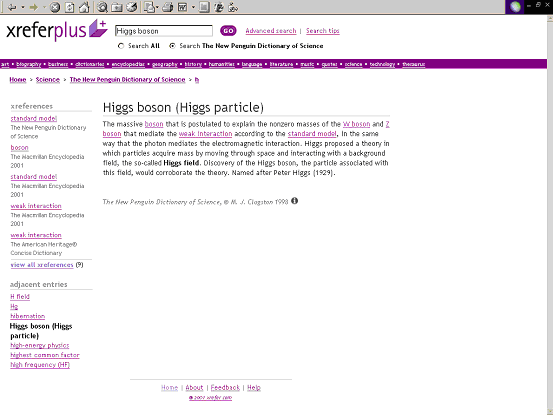
Figure 1: An entry from the New Penguin Dictionary of Science with five cross-references.
(Note that some of the xreferences appear in the column on the left).
One can think of each reference book (in the sense of a book with cross-references) as being composed of a collection of entries, and running through the whole collection is a pattern or network of cross-references, connecting entries in the book in topic-specific relationships. In web terms these cross-references are easily translated to navigable hyperlinks, but it is a remarkable fact that many reference works have been transferred to the web without this basic feature being implemented. Each book in an aggregated collection of reference works will have its own network or pattern of cross-references. And at xrefer we are of the view that it is extremely helpful for the the user of one work if she is able to explore the connections and topics which might be relevant to her interest in any other work in the collection; we call these xreferences. A cross-reference is a reference through a topic-link (the word on which the link is anchored gives the topic); an xreference is a reference to another entry in a different reference work through a topic-link. The ‘standard model’ cross reference in the body of the ‘Higgs boson’ entry takes the reader to the ‘standard model’ entry in the book she is consulting, whereas an xreference to ‘standard model’ will typically take her to an entry on the ‘standard model’ in another book, eg the Macmillan Encyclopaedia (see Figure 2). An individual reference work has its own pattern of cross-references and a collection of cross-referenced reference books has its own pattern of xreferences.
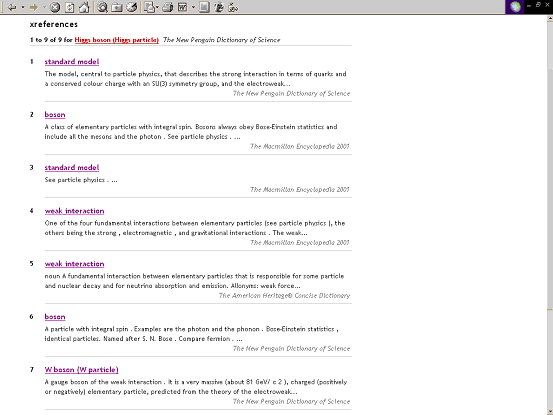
Figure 2: 9 xreferences from the’ Higgs boson’ entry in a Penguin book
xrefer was founded with the aim of building a collective reference resource which as well as aggregating diverse reference works also provided a browsable (integrated) network of xreferences between them. In practice it has been feasible to build a system which is highly scalable (in the sense that it should accommodate thousands of titles) and which also seems to get better, in some important respects, as more content is added to the system. If a wide range of reference works can be mobilised for web deployment in a consistent and common framework, users have a highly searchable and browsable reference engine – better in practice than any physical library.
Implementation and technical development
In designing a system which would aggregate and integrate a large number of reference works we made some crucial early strategic decisions.
- a.All the books would share a common DTD (document type definition).
- b.The system would be built on XML (in the end we decided we needed our own DTD which we call RML – Reference Markup Language). Our encoding system has grown and will continue to be improved: the current version supports about 50 tags(6).
- c.We would attempt to capture as much as possible of the implicit structure as can be deduced from the typographical and stylistic encoding of a published book. We have content experts who analyse every new book to this end. We are careful not to ‘throw away’ structure even if we can see no way of currently using it.
- d.We outsource almost all the data capture and parsing involved in upgrading publisher-supplied texts to the polished, RML encoded, version.
- e.We developed software which validates any RML file to check that all the references are properly matched (very often reference books have ‘hanging’ cross references).
- f.We developed software (a suite of algorithms) which allows us to generate appropriate and validated xreferences connecting entries in different books.
- g.The finished texts and the cross-references and xreferences are held in a relational database which is used to build a range of web services.
- h.The system has some business logic at the foundation level. For example: we manage and build the system using the individual books as components. But the books themselves are collections of entries and every entry is explicitly associated with the copyright line appropriate to the book from which it is derived. Also each entry will have a group of xreferences which are specific to that entry, but we are careful not to present the xreferences as part of the entry. They are a property of the xrefer system and the system should not interfere with the entries as they were conceived by the original compiler or editor.
It was also a requirement of the system that it should be a scaleable system. This meant, in particular, that the process of building xreferences should be entirely driven by software and database systems. Each book gets individual attention and care when it enters the production system, but once the RML file has been built the process of generating cross-references and xreferences should be completely automated. If the system depended on human editorial effort to build xreferences it would gradually slow down and seize up as more content was loaded into it.
Navigation, searching and classification
In building the xrefer system we have concentrated on techniques for developing enhanced navigation within collections of reference works. Developing systematic ways of navigating reference material improves ‘searching’ and leads to a rich system of classification of the data, but these are by-products of the system. The ‘searching’ technology in xrefer is no better than we can find in the best ‘off the shelf’ search engines. As it happens, the first generations of xrefer’s service have used the RetrievalWare search engine from Convera(7), but this is not an essential feature of the system. It would be possible to use another search engine – if there are clear advantages in doing so. ‘Classification’ is another important aspect of reference material on the web. Indeed classification systems have been important to compilers of reference works from the seventeenth century. Many reference works are built on the framework of an agreed classification system. The original task that inspired xrefer might have been tackled using an existing classification schema (eg the Open Directory). So, one might find a method for sorting entries from different books into the most relevant node in the Open Directory(8). In fact, we took an early decision to be completely agnostic about ‘classification systems’. Classification systems matter to xrefer only to the extent that every reference book is in effect a way of classifying its subject matter. A musical dictionary will contain the names of musicians and is therefore an implicit way of classifying famous persons as musicians, and a Biographical dictionary of scientists will be a way of grouping scientists. The xrefer system will absorb these classifications without ‘requiring’ that ‘persons’ are classified in any specific fashion. All reference works use classification systems and xrefer is committed to capturing the information in these systems without giving any of them an over-arching priority. So xrefer uses classification systems and they are very important to the users of xrefer services, but the classes of objects that the system ‘knows about’ are all derived from the collection of books that have been processed. A different collection of books would have produced a different system of classifications.
xreferplus and customisable reference services for libraries
xrefer was launched in June 2000 as a free (advertising and sponsorship backed) reference resource at xrefer.com. This free resource remains as a shop-window and demonstrator of the xrefer technology but it was never likely that specialised reference works could be viably distributed through an advertising vehicle and personal subscriptions or micropayments still appear to be a distant prospect on the web. In the course of 2001 the company has been developing a significantly larger and ‘higher value’ collection of major reference resources which will be offered as a library subscription from December 2001. xreferplus is a collection of over 100 reference works which should form a valuable and broad starting point for any library’s on line reference resources(9). The collection is deliberately broad (with sections for history, art, biography, language, literature, music, science and technology), as well as a dozen or so large general reference encyclopaedias, quotations books, thesauri, dictionaries etc.
There is some temptation to carry on adding books into the system - and we fully intend to succumb to the temptation; but it is also clear to us that there will be even more value in creating increasing opportunities for librarians and information specialists to build their own selections of reference resources from a palette provided by xrefer. The xreferplus collection is probably already too rich and specialist to be entirely suitable for school subscribers; and there is scope for regional selection and customisation. Although we have started by offering a common global solution for any English language libraries, it is clear that librarians who use an integrated reference service will come to prefer a solution which they can fashion to suit the needs of their own clients. To take some examples of books which xreferplus currently lacks: Who’s Who in Canada is likely to be one of the most valuable reference works for Canadian libraries, but it may not be a top priority for librarians in Coventry or Melbourne. A field guide to British birds will be a sought after resource in British public libraries, but it will not be prime pick in San Diego. The case for differential offerings and customer selection is at its strongest in the case of languages other than English. The production and database system developed by xrefer is in no respect an ‘English language’ system and it is now a priority to develop links with publishers of reference material in the other European languages. For many libraries and most users a comprehensive coverage of reference material in the major European languages may be more than is needed; but the possibility of selecting the appropriate combination of language materials will be important to many users and many educational and corporate subscribers. A multi-lingual xrefer will be the next challenge. More generally, although aggregation and integration lead to powerful reference resources, the ability to customise and select particular collections for specific contexts is also important. Scalability is a key requirement for a large reference resource, but a truly scaleable solution will be one that can scale down as gracefully as it can scale up.
References
- (1) Yourdictionary.com lists 1,800 dictionaries covering 250 languages http://www.yourdictionary.com/index.shtml
- (2) The OED online development cost $1.4 million before any marketing or support costs are taken into account see ‘How the Oxford English Dictionary went online’, Laura Elliott, Ariadne 24, http://www.ariadne.ac.uk/issue24/oed-tech/
- (3) Infoplease has been acquired by the Pearson group and is now part of the learning network. http://www.infoplease.com/ . Bartleby is a mixed reference and full text resource strong in literature and history http://www.bartleby.com/
- (4) Microsoft’s Bookshelf, now withdrawn, an offering which was a collection of reference books designed to help in the task of writing was a client-side solution
- (5) The issue of aggregating and integrating citations is of great importance in electronic publishing and a significant start has been made on creating a solution by the publishers’ consortium CrossRef http://www.crossref.org/
- (6) RML can be inspected from the source of any entry in xrefer services. The specification is also freely available to interested parties.
- (7) http://www.convera.com/
- (8) Google has developed the technology for linking web searching and web classification (using the Open Directory as the classification system). It might be interesting to ‘integrate’ a reference collection with the Open Directory in a similar fashion and xrefer’s collection of xreferences would be one means of doing this.
- (9) The contents of xreferplus are at http://www.xreferplus.com/allbooks.jsp
Author Details
|