An IMS Generator for the Masses
One of the aims of all JISC 7⁄99 projects has been to explore technologies that are generic in nature in support of improved learning and specifically, to “Identify the generic and transferable aspect of the development projects”.
In pursuit of this aim, the MARTINI Project has been specifically standards-driven. One of the standards that we have employed is the IMS Enterprise Person Object Model for representation of student information. As has been discovered, however, there are two fundamental obstacles to overcome with the use of the IMS standard; one, the standard only covers a small subset of the information any institution holds about a student, and two, there is a diverse array of systems and architectures that hold this data within each institution.
MARTINI’s solution has been to create an ‘IMS-Generator’ which not only can create the IMS extensions necessary to hold the data but also allows for the creation of IMS-conformant XML files of any and all data held by an institution, regardless of ‘native’ format and/or structure. Indeed, the MARTINI IMS-Generator ‘toolkit’ can be used to transform records from specified databases to any standard, not just IMS Person Object Model. Use of this type of ‘middleware’ eliminates the need to recode the toolkit in order to satisfy a particular task.
This article will outline what exactly the IMS Generator does, how it does it, and what implications this might have for the development of MLEs (Managed Learning Environments), particularly in the HE community. It will draw heavily on existing work by MARTINI Project staff [1], but will attempt to explain the concepts within the IMS Generator in a non-technical manner, and without inclusion of streams of code.
General Architecture
As shown in Figure 1 below, the basic architecture of the IMS-Generator is essentially quite simple. In order to retrieve records from a particular database, the database connectivity drivers must be in place. The general approach of IMS-Generator is to create a configuration file in XML format (rdbms.xml). Its contents are then formatted into an instance of a Java object named RDBMsDetails.java. This instance will then be used to connect to specified databases and retrieve records from those databases. At University of East Anglia (UEA), JDBC (Java Database Connectivity) is used but the IMS-Generator can also cope with ODBC (Open Database Connectivity).
Those retrieved records will then be formatted into portions of XML code which are finally created as a temporary XML document (temp.xml). The elements in temp.xml are created using the internal field names of database tables. An eXtensible Stylesheet Language Transformation, (XSLT) stylesheet (build-ims.xsl) is applied to temp.xml to create an XML document conformant with the IMS Person Object Model which is named ims.xml.
Finally, the ims.xml file is used to create a set of HTML pages (presentation layer) by doing transformation with a set of XSLT stylesheets.
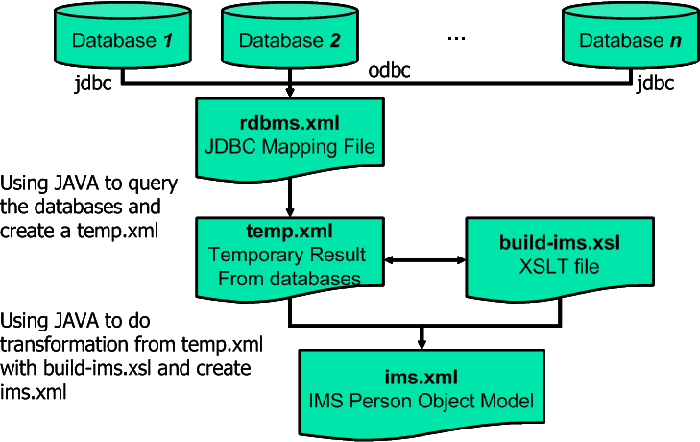
Figure 1: Basic architecture of the IMS-Generator
Database Connectivity Mapping
The initial requirement for the IMS-Generator is simply to connect to resident institutional databases. In the UEA version of IMS-Generator, pure JDBC technology is mainly used to communicate with databases. However, the JDBC-ODBC Bridge technology is also used occasionally for talking to databases that use ODBC.
The JDBC information for any database is stored in the XML file, rdbms.xml. The properties element imbedded within the file contains the JDBC properties necessary for connection to a database. Within the properties element, there are four child elements that contain specific information matching a JDBC driver to a particular database.
There is another element within the rdbms.xml file named additional-properties, which provides additional JDBC information, where necessary. This allows for addition of connectivity information without recoding the entire file. As many elements as necessary can be included within additional-properties.
Multiple databases pose no problem for the IMS-Generator. Any number of rdbm elements can be created as child elements of the root rdbms element. Each rdbm child element holds all the information necessary for connecting a specific database. Each will contain, where necessary the elements noted above; i.e. properties and additional-properties. Adding another rdbm child is straightforward - simply copy an existing rdbm element and modify the data therein to represent the new database that is being included.
SQL Statements Preparation
This area of the IMS-Generator constructs the queries that will extract data from the resident institutional databases. It does this by way of execution of SQL statements. Within rdbm.xml, these statements are held in a statements element, which in turn, contains child elements called statement. Each statement element has a child element named query which is where the standard SQL statement (i.e. query) is held. An example of this is shown below:
<statements> |
The XML attribute groupTagName of the statement element creates a pair of XML tags that are used to group the result from querying the database with the specified SQL statement. Using the above example, if one wishes to group the results for this SQL statement by an XML element named familyname, simply set this attribute to be groupTagName=“familyname”.
Where there are multiple values records with the same element within a database (e.g. surnames in the above example), the result for the SQL query will be formatted into XML format under the attribute groupTagName. In this case, this has been set equal to “familyname”, and therefore the query result will be grouped by the familyname element. Each of these retrieved surnames is created as a SURNAME element because IMS-Generator, by default, uses the local name of the field of the database table as tag name for the XML element created. This SURNAME element will then be embedded by the result element that is coming from IMS-Generator. The number of result elements is dependent on how many records are returned when a specified SQL statement is executed.
Creating multiple SQL statements for a particular database is relatively easy. One simply adds an additional statement element within the statements element that contains a unique groupTagName attribute and a query child element to hold the new query. The number of statement elements is unlimited. However, the statements element can only contain queries for one database, as it is limited to the database defined in the rdbm element in which it is found.
If IMS-Generator has to access multiple databases, it creates a rdbm element for each of the databases. The configuration of this element is exactly as noted above, save that the values and properties of the new database need to be included.
Retrieval and Formatting of Query Statement
The process outlined so far has been preparation for the heart of the IMS-Generator functionality, i.e. the retrieval of information and its conversion into IMS-compliant XML for later representation in a presentation layer. This section outlines the first process, i.e. the retrieval of the results of a query statement.
Assuming that all above has been done correctly, the contents of rdbms.xml (which contains the results of the SQL queries) is converted to an instance of RDBMDetails.java. This instance is made up of JDBCProperties.java and StatementDetails.java; the former containing the properties element of the rbdms.xml and the latter the statements element of the rdbms.xml file.
If there is more than one database to be accessed, IMS-Generator will create multiple instances of RDBMDetails.java Java objects. The number of instances of RDBMDetails.java depends on how many databases are to be accessed. Finally, IMS-Generator puts these instances of RDBMDetails.java into a vector that is then saved as an instance of a Java object, RDBMsDetails.java. Figure 2 in shows this process in graphical terms.
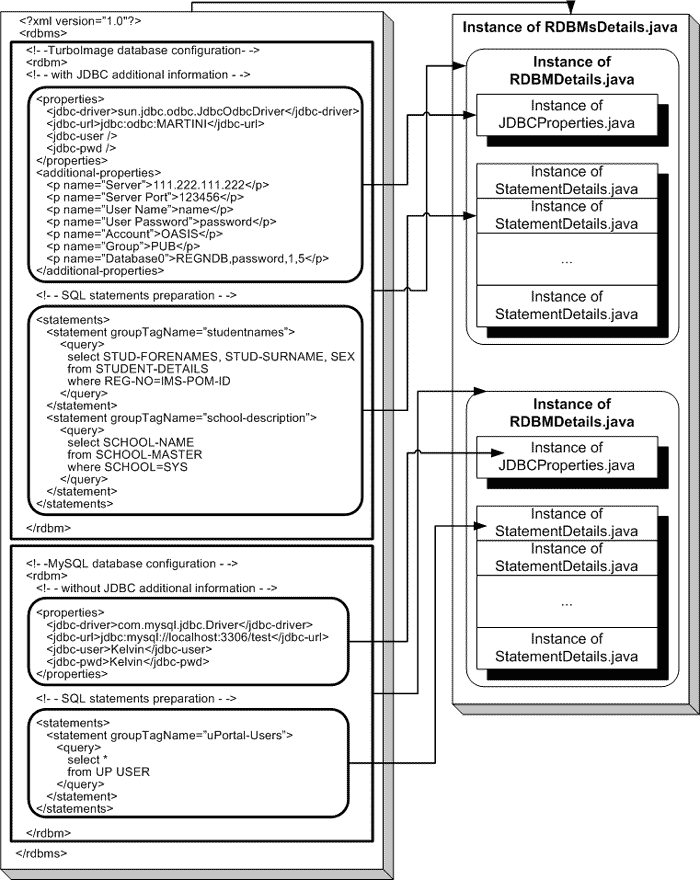
Figure 2 - Conversion of contents of rdbms.xml to RDBMsDetails.java
The IMS-Generator uses these instances of StatementDetails.java as the SQL statement for querying the corresponding databases and stores the retrieved records in an instance of the Java object String, which will eventually be written to a local file storage. However, IMS-Generator does a reformation of the resultant records into XML format before the instance of the Java object, String, is written to a local disk.
Transformation to XML
The data recovered is now ready to be converted to XML.
A retrieved record can contain as many fields/attributes/columns of a particular database table as necessary. There are two ways for IMS-Generator to deal with the field/attribute/column names: In the first case, the field names are declared within the SQL statement. These field names will be used to create XML elements.
In the second case, the field names are not declared in the SQL statement, as shown in the following portion of XML code; in which case, IMS-Generator actually reads the field names corresponding to that SQL statement automatically.
<statement groupTagName=‘uPortal-Users> |
If there were, for example, 6 columns in the above UPUSER table, IMS-Generator reads the field names and uses them to create a set of XML elements with corresponding retrieval results as their text value as seen below:
<USER ID>RetrievalResults</USER ID> |
Turning to the contents of these retrieved records, again the IMS-Generator is able to deal with either singular or multiple records, using the same methodology.
Portions of XML code are created to represent each of the retrieved records, regardless of the number of records. These are each held within a separate result element that contains both the field/attribute/column names and the records within each of those separate fields/attributes/columns as child elements.
The difference between single and multiple records is simply the number of result elements created with the above characteristics. For single results, only one is created; for multiple results, as many are created as necessary.
The attribute groupTagName is used to gather the various result elements. The IMS-Generator uses the groupTagName created previously for the SQL statement to create an XML element in which all the result elements are placed. In the example above of UP_USER, where there are multiple records, the code would appear as follows:
|
Where a groupTagName attribute does not, for whatever reason, exist, the IMS Generator uses a default value, RESULT_Without_GroupTag_Specified of attribute groupTagName, to create a parent element within XML that will hold the result child elements. In the above example, if no groupTagName attribute existed, RESULT_Without_GroupTag_Specified would be seen/used where uPortal-Users is seen/used.
All the retrieved results are integrated through the creation of an auxiliary database, temp.xml, as a root document holding all the elements created so far. Figure 3 below illustrates this process. There are 2 instances of RDBMDetails.java, one containing 2 instances of StatementDetails.java and the other only one (our uPortal-Users from immediately above). A portion of XML code is created for each instance of StatementDetails.java (portion A, B, & C in Figure 3). The root element created to hold all of this is named enterprise. All the results child elements and groupTagName elements created previously are retained and held within the enterprise element. The name of the root element is hard coded in the Java class named RDBMs2XML.java. If this name is to be changed, the source code has to be modified.
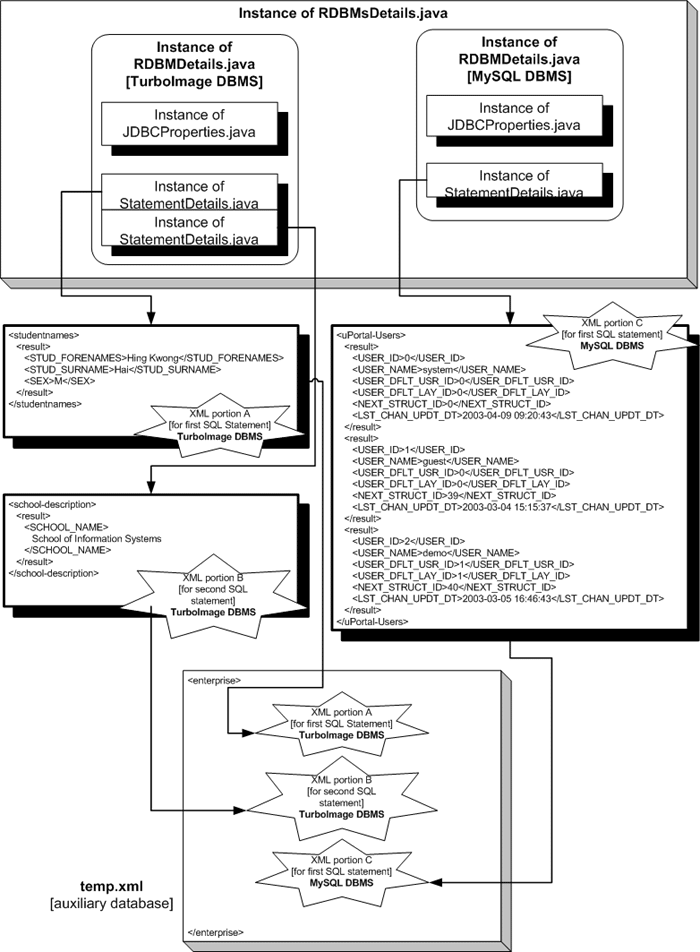
Figure 3 - Integration of retrieved records and creation of temp.xml
This structure is completely flexible and imposes no limits on the number of XML portions that can be held within the enterprise element. If the resultant temp.xml file is too big for the hardware in place, multiple temp.xml files can be created. A tool named XMLMerger.java that is described at greater length below will merge these.
Creating IMS-compliant XML
The temp.xml document now created retains the structure of the underlying data. It now has to be transformed into a standard format; in the case of MARTINI, IMS.
This is done by the use of eXtensible Stylesheet Language Transformation, (XSLT). This is a simple process using an XSLT document entitled build-ims.xsl. Figure 4 models this process.
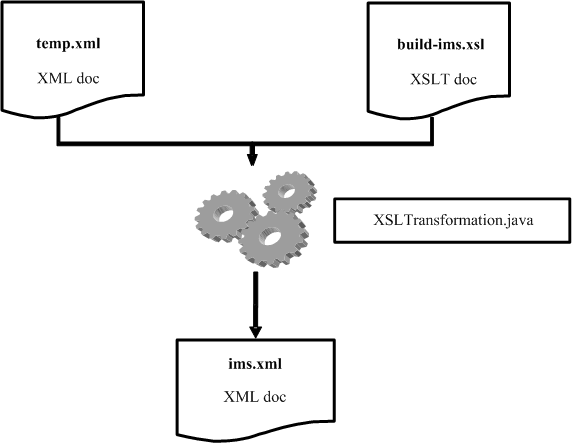
Figure 4: Conversion of temp.XML to IMS Person Object Model
The resultant document of this process can be a text, HTML or XML document. The Java class, XSLTransformation.java, works with both temp.xml and build-ims.xsl to create the final document.
The instance of XSLTransformation.java does not actually do anything special. The clever bit is in the XSLT document, build-ims.xsl, which allows the transformation of an existing XML document to another document in various formats. More importantly, it allows the conversion of an existing format or standard to another widely used standard such as IMS which has been used in MARTINI Project.
XSLTransformation.java uses three parameters, String xmlFileName, String xslFileName, and String outFileName, which are instances of the Java predefined object, String. The xmlFileName is the url of a source XML document, temp.xml; The xslFileName is the url of an XSLT document, build-ims.xsl and the outFileName is used to store the destination url of a resultant file. Suppose the temp.xml and build-ims.xsl exist in the current working directory, and we want to create a resultant XML document named ims.xml for the transformation in the same directory, what one would need to do is create an instance of XSLTransformation.java as shown below.
XSLTransformation xslt = new XSLTransformation(“temp.xml”, “build-ims.xsl”, “ims.xml”; |
One of the key advantages IMS Generator is that approach it takes allows to create ‘extensions Enterprise format ‘on fly’ by definition extension fields in the build-ims.xsl file. This file also ‘pulls relevant underlying data from the temp.xml files, which results appearance an extension element within the resultant ims.xsl holds the extensions to the IMS Enterprise standard.
Actual coding details of how how accomplished are held a in a technical paper [1] available on the MARTINI website [2].
Merging Multiple XML documents
As noted above, there may be occasions when more than one temp.xml file might need to be created by the IMS Generator. Earlier iterations of the MARTINI IMS Generator that used WebObjects made extensive use of the XMLMerger engine but subsequent enhancements of the system have meant that only one temp.xml document is now created. However, the XMLMerger is still a very useful tool for merging existing XML documents into an IMS-compliant record in XML format.
Within the IMS Generator, the XMLMerger.java engine is simply a Java class which transforms an XML document (which specifies the URLs of the source XML documents) with a XSLT stylesheet for merging into an entire resultant document in XML format. Figure 5 below shows the basic architecture of the XMLMerger.java engine.
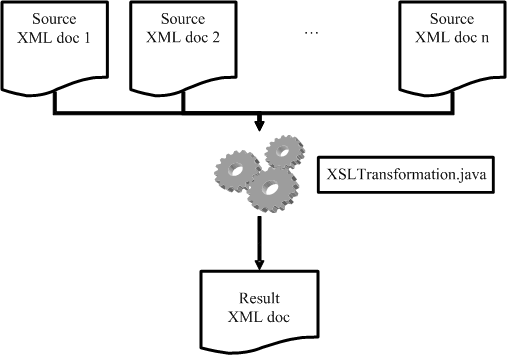
Figure 5: Basic architecture of XMMerger.java
XMLMerger.java inherits XSLTransformation.java, the engine by which an XML document is converted into an IMS-compliant XML document. The XMLMerger Java class also includes source.xml, a file that specifies the source XML documents to be merged and merger.xsl, an XSL stylesheet that specifies how to merge the source XML documents identified in source.xml.
Finally, XMLMerger.java has to be called to perform the transformation of source.xml with merge.xsl to create a resultant XML document, mergedresult.xml which stores the result after merging the specified XML documents. Once again, as noted above, the results are held in an extension element that supplies an IMS conformant structure.
Presentation of data to end user
Currently, many organisations and institutions are using XML documents as data sources rather than building XML-based applications. More precisely, organisations and institutions tend to use the XSLT technology for transforming XML documents into other documents with different formats such as Text, different XML and majority HTML pages.
As one of objectives of MARTINI project is to provide a Web-based front-end application for students, we create HTML pages for the presentation layer. This is done by transforming the IMS-conformant data held in the XML document ims.xml, with a set of XSLT stylesheets. This is shown in Figure 6, which illustrates a basic architecture of building HTML pages on top of the IMS standard.
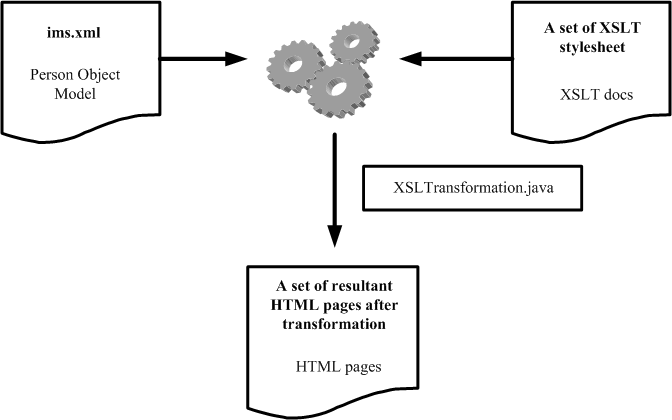
Figure 6: Creation of HTML pages from IMS Person Object Model
The process is as described earlier. It is quite simple, performing transformation from ims.xml with a set of XSLT stylesheets, which tells the Java class XSLTransformation.java to produce different HTML pages as resultant documents. The details of this are shown in Figure 7.
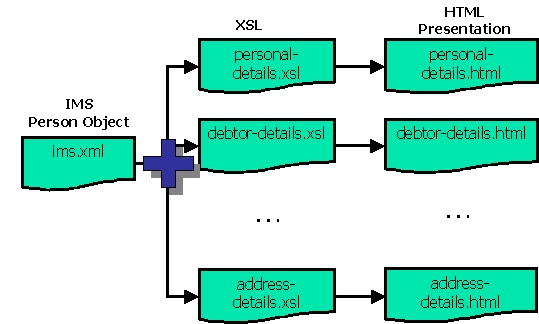
Figure 7 : Creation of HTML pages from IMS Person Object Model (detailed)
The MARTINI IMS-Generator is not only able to transform data from institutional specified databases to IMS Person Object Model format, but can also transform the specified data structure to any standard. All that is required in order to use IMS-Generator to conform your institutional specified data to another standard is to modify build-ims.xsl so that it specifies the way to format your data to another standard.
Indeed, the MARTINI Project has found value in the IMS Generator in unanticipated ways. It has been used, for example, to convert the contents of a CVS file containing survey results of 300 UEA students into an Excel format that allows for easy manipulation and analysis.
Accessibility is an increasingly important issue when developing Web-based applications and a lot of effort to make their Web pages accessible for potential users who have difficulties in viewing the page. As all HTML pages created via IMS-Generator use the XSLTransformation.java to transform the IMS-conformant file, ims.xml with differing XSLT stylesheets, it is pretty simple to address the accessibility issues by using an XSLT stylesheet with the appropriate format so that accessible Web pages can be generated.
VoiceXML is another choice for addressing part of the accessibility issue. The ims.xml file can easily be transformed to VoiceXML as long as a set of appropriate XSLT stylesheets are provided. VoiceXML applications can then act as a screen reader to help students with difficulty reading the normal computer screen.
Many mobile devices nowadays are able to browse Web pages. However, the content these devices can access is limited. WML is a subset of XML technology which allows access to simple web pages for mobile devices. Again, it is extremely easy to conform institutional data to a set of Wireless Markup Language (WML) documents provided a set of XSLT stylesheets have been created that will allow the IMS-Generator to do the transformation.
Conclusions
Whilst this article, and the MARTINI Project for that matter, has concentrated on the creation of IMS-compliant XML, the IMS Generator’s flexibility as shown above allows it to be a tool of on-going value to the MLE community. As new standards emerge, the IMS Generator will be able to adapt and remain useful.
The use of standards such as XML, XSLT and Java are also critical to the future of the IMS Generator. This will permit development of the IMS Generator itself, and will also mean that it is embedded in the mainstream of technical developments within the MLE community.
On a related point, as the IMS-Generator is developed in pure Java programming language and with XML technology, it is capable of being executed on different platforms. The implementation of XML and XSLT technologies also provides an easier way for people in other institutions to use this toolkit without requiring solid Java programming skills. However, knowledge of SQL, XML and XSLT is required for configuring IMS-Generator.
In short, we believe the IMS Generator to be inexpensive, useful, sustainable, and easily integrated by a wide range of institutions; a tool for the ‘masses’.
References
- Hai, (Kelvin) Hing Kwong. IMS-Generator Description - Technical Paper. (unpublished ms.) May 2003.
- MARTINI Project website http://www.mis.uea.ac.uk/martini/
Author Details
(Kelvin) Hing Kwong Hai |
David Palmer |
Chris Dunlop |
Article Title: “An IMS Generator for the Masses”
Author: K. Hai, D. Palmer and C. Dunlop
Publication Date: 30-July-2003
Publication: Ariadne Issue 36
Originating URL: http://www.ariadne.ac.uk/issue36/martini/