Improving the Quality of Metadata in Eprint Archives
Throughout the eprints community there is an increasing awareness of the need for improvement in the quality of metadata and in associated quality assurance mechanisms. Some [1] feel that recent discussion of the cultural and institutional barriers to self-archiving, which have so far limited the proliferation of eprint archives in the UK, have meant that anything that is perceived as a barrier between academics and their parent institutions needs to be played down. However, ‘metadata quality has a profound bearing on the quality of service that can be offered to end-users…and this in turn may have a detrimental effect on long term participation.’ [1]. Therefore, this article suggests a number of quality assurance procedures that people setting up an eprint archive can use to improve the quality of their metadata.
Importance of Metadata Quality
Quality is very difficult to define. A definition that can be used in the context of metadata is: ‘high quality metadata supports the functional requirements of the system it is designed to support’, which can be summarised as ‘quality is about fitness for purpose’.
Metadata quality is a particular problem for the eprints community for two reasons. Firstly, within eprint archives, metadata creation is often carried out by document authors as part of the deposit process; yet there remains a lack of good (and configurable) metadata creation tools that support the untrained end-user in this task. Secondly, in order for end-users to benefit fully from the development of eprint archives, service providers need to maintain a high level of consistency across multiple data providers. In other service areas, where this high level of interoperability is not as important, lower metadata quality may be more easily tolerated. In eprint archives, metadata quality influences not only the service offered through the archive’s native Web interface, but also what options can be offered by OAI service providers like ePrints UK [2]. Some of the quality assurance points noted below, such as defining functional requirements, may need to be articulated at both levels. Groups of data providers, e.g. those within a particular project or initiative, may want to define requirements cooperatively with appropriate service providers, and from those outline the minimum ‘quality’ requirements for participating data providers.
Deciding upon Metadata Quality
Before starting work on the creation of an eprint archive the following four assessments should be carried out:
1. Define the ‘internal’ functional requirements relating to the archive’s Web user-interface
To decide what metadata is needed, you should decide what the archive is trying to achieve and what your end-users will want to do with the metadata held. The easiest way to define this is to write a full list of requirements relating to the eprint archive’s Web user-interface. An example list of functional requirements is given in Table 1.
It may also be useful at this stage of the project to attempt to define the browse tree structure required for certain metadata fields. This will allow you to decide upon the level of granularity required in the controlled vocabularies at a later stage. For example, dc:type (which describes the nature or genre of the resource) might be used to ‘filter’ search results. This would allow the user to filter search results by journal article, book chapter, thesis, etc.
Example of Functional Requirements List We would like users to be able to: Search records by:
Browse records by:
View latest additions to the archive We would like to be able to: Link together records from the same:
Filter by:
|
Table 1: A functional requirements list
2. Define the ‘external’ functional requirements relating to disclosed metadata
The next step is to define all the functional requirements relating to the exposure of your metadata to external services using the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH). This list may be similar to the previous list because you may want to allow external services to carry out similar actions on your metadata. However it is likely that the list will be shorter because you have little control over the functionality offered by external services. Note that your external functional requirements are likely to be heavily influenced by the functionality of existing Open Archive Initiative service providers.
3. Define a metadata ‘application profile’ that will support the listed functional requirements
Once the requirements have been established, it should be possible to define the list of metadata elements, encoding schemes and controlled vocabularies needed to support the requirements.
Controlled vocabularies are an essential part of the metadata in an eprint archive, e.g. for subject terms, resource types, etc. It will be necessary to decide whether to adopt existing vocabularies or to create new ones. In general, using existing, externally-maintained vocabularies is more likely to lead to interoperability with other systems, which may be important in meeting the ‘external’ functional requirements identified in 2. above.
Note that there may be other constraints at this stage, for example the OAI-PMH requirement to support simple Dublin Core.
4. Define ‘content rules’ for the values used within your metadata
Metadata quality can be assessed by determining whether the metadata in the eprint archive is good enough to support the functional requirements defined above. For example, where dates are used as metadata values it is important to have content rules specifying the format of those dates. If the date format is not specified, and different date formats are used when documents are deposited, it may not be possible to sort those documents by date. As a result, users will not be able to search or browse documents by date. If searching and browsing by date are listed as functional requirements for your eprint archive, then your metadata will not be of sufficient quality to meet your functional requirements. Similarly, if you have a requirement to browse author names alphabetically, then you need to ensure that author names are entered in a controlled form (e.g. family name first).
Martin Halbert, as part of various Mellon Foundation-funded projects, has looked at issues of metadata quality in OAI-based services, including what he calls ‘collisions’ between metadata formats, authority control and de-duplication issues [3]. More problem areas relating to the quality of metadata for both learning objects and eprints are outlined in a recent paper by Barton, Currier and Hey [1].
Achieving Metadata Quality through QA Mechanisms
Deciding upon the metadata quality needed for your eprint archive is only the first step in achieving metadata quality. In order to achieve quality as defined, what is needed is a quality cycle that should be built into your eprint archive from the outset. This cycle consists of a number of elements:
A. Produce cataloguing guidelines
Once the metadata schema to be used by an eprint archive has been defined, a set of cataloguing guidelines should be produced. These guidelines should define all metadata elements that are to be used, give content guidelines for each - including information on the particular standards in use - and some examples. They are essential in ensuring a minimum level of consistency between eprint records [4].
B. Improve the usability of metadata entry tools
In order for the cataloguing guidelines to be used effectively, it is important that they are imbedded within the input tools in some way. Note that the design of metadata creation and editing tools is a non-trivial activity and that issues relating to the usability of these tools is not tackled in this article. However, a simple example of how integration of guidelines can be carried out is shown by the RSLP collection description tool [5]. The data entry guidelines may be made available as a separate document, from within the editing tool in the form of explanations and examples, or both.
It is important to remember that inconsistent application of controlled vocabularies will have a negative effect on the functionality of the eprint archive. In order to avoid this, there may be ways of changing the interface of metadata editing tools to support their consistent use, e.g. through the use of ‘drop-down’ boxes or links to authority lists.
C. Implement appropriate quality control (QC) processes
Once the application profile, controlled vocabularies, cataloguing guidelines and data entry tools are in place and metadata is being entered into the eprint archive, it is important to make sure that they are having the correct impact on the quality of the metadata being created. Their impact can be tested by implementing suitable QC processes within the metadata input workflow. For example, once a month a random sample of metadata entered could be sent to an information specialist for assessment.
The National Science Digital Library (NSDL) uses a commercially available visual graphical analysis tool called Spotfire DecisionSite [6] to carry out tests on random samples of metadata. They found that the software significantly improved efficiency and thoroughness of metadata evaluation. Their methods and findings are documented in the paper by Dushay and Hillman [7].
Paul Shabajee of the Arkive Project [8] has recently carried out some work on inter-indexer consistency. An automated system has been scoped that allows the system to feed resources out to cataloguers in the form of a ‘cataloguing to-do list’. The system can throw a small percentage of images/items to all (or a subset of) cataloguers. This means that sometimes the same resource is sent to more than one cataloguer and the results are compared and inconsistencies flagged and examined. Naturally, inconsistencies do not always mean an inaccuracy and there are a lot of complex semantic issues that need consideration. The system then collates the statistics and provides dynamic feedback on consistency. This in turn feeds back into other QA processes. Within the project it is felt that if the indexing within a system is inconsistent then it does not matter how good the information recall system is, the service will ultimately fail. The recall and precision of the system are fundamentally limited by the underlying consistency. Advantages of the scoped system would be that once it is set up there is a very low overhead and results are provided from real daily work and not special QC survey activities that are likely to skew results by making the cataloguers behave, probably subconsciously, differently to normal [9].
In order to put more value on the information obtained by assessing random samples of metadata, it is probably useful at this stage to look at the metadata creation workflow models that are commonly in use. Most eprint archives make some use of automated metadata creation during the document deposit process. This automation can vary from full automation, for example when assigning the dc:format of a document, to semi-automation, for example when a title is automatically extracted from a document but is then presented to the document author (or whoever is depositing the document) for manual checking. However, not all metadata fields benefit from a full or semi-automated approach. In these cases manual cataloguing must be carried out by the document author or by an information specialist. When assessing random samples of metadata it may be useful to assess the quality of automatically generated metadata by considering how often the document author has to amend it. Looking at this aspect of the metadata created would allow steps to be taken to improve the automated service. Similarly, it may be possible to analyse how often information specialists need to modify the metadata supplied by the document author, with steps being taken to improve the cataloguing guidelines and metadata entry tools being offered to the document authors as a result.
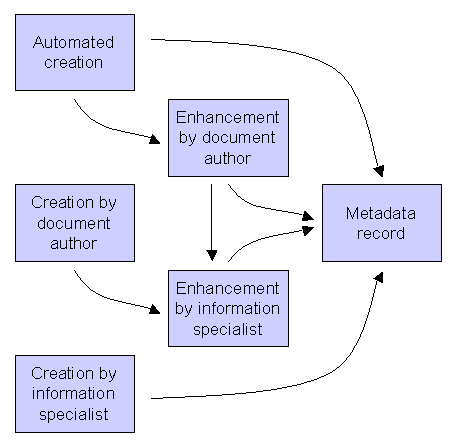
Figure 1: Metadata creation workflow
It is important that whatever constructive feedback is obtained from testing be passed back into the system through redesigns of the application profile, controlled vocabularies, cataloguing guidelines and data entry tools. This QA process can be viewed as a cycle or feedback loop, in that each stage feeds into the next, (see Figure 2). Processes, standards, tools and documentation are iteratively enhanced with the overall aim of improving the metadata created. When good Quality Assurance is implemented there should be improvement in the quality of the metadata, the usability and performance of the eprint archive and there should be a decreasing rate of defects. Defects here refer to the problem areas defined by Barton, Currier and Hey [1].
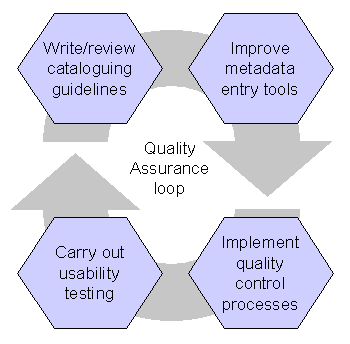
Figure 2: Quality assurance loop for metadata
D. Carry out usability tests
Another QA mechanism that needs to be put in place is a form of testing to ensure that end-users are able to undertake the activities specified in the initial functional requirements. The most straightforward way of testing this is through usability tests. These usability tests need to be well designed in order to differentiate clearly between testing of the metadata quality and the overall usability of the eprint archive.
The Targeting Academic Research for Deposit and Disclosure (TARDis) Project [10] has been funded as part of JISC’s Focus on Access to Institutional Resources Programme (FAIR). The project itself will be building a sustainable multidisciplinary institutional archive of eprints to leverage the research created within Southampton University using both self-archiving and mediated deposit. However, while developing the archive, TARDIS will be passing feedback back into the GNU eprints software [11] developed at the University of Southampton. To do this they are trialing a simpler interface to eprints software for author-generated metadata and testing the value of a number of areas. These include: targeted help; more logical field order; examples created by information specialists and fields required for good citation.
Conclusion
As more work is carried out in the area of eprints there is an increasing realisation that the metadata creation process is key to the establishment of a successful archive. There is still much research work to be done in areas such as consideration of the processes involved and the use of metadata tools. However this article has outlined a number of procedures through which those setting up eprint archives may be able to improve the quality of the metadata being produced for their own service and external service providers. The consistent application of relevant metadata is extremely important in supporting the creation of high-quality services based on it. In order to achieve this, data providers need to consider their own functional requirements and those of relevant service providers. They also have to define an appropriate metadata application profile to support these requirements and make clear decisions on the quality levels needed for them to operate properly. The provision of cataloguing guidelines and authoritative information on controlled vocabularies can help support the metadata creation process, e.g. by being incorporated in metadata editors. Finally, there are a number of quality assurance techniques that can be used to measure the quality of the metadata after it has been created. These include the evaluation by information specialists of random samples and the use of graphical analysis tools. It may also be possible to focus on improving eprint deposit and metadata creation workflows and to undertake some usability testing of the archives while they are being developed.
References
- Barton, J; Currier, S & Hey, J. (2003) Building Quality Assurance into Metadata Creation: an Analysis based on the Learning Objects and e-Prints Communities of Practice, DC-2003.
http://www.siderean.com/dc2003/201_paper60.pdf
Powerpoint available from
http://tardis.eprints.org/papers/ - ePrints UK
http://www.rdn.ac.uk/projects/eprints-uk/ - Halbert, M. (2003) The MetaScholar Initiative: AmericanSouthOrg and MetaArchive.Org, Library Hi Tech, 21(2), 182-198. Available (in HTML and PDF) from the Emerald Library
http://www.emerald-library.com/ - Using simple DC to describe ePrints. Powell, A, Day, M & Cliff, P. (2003)
http://www.rdn.ac.uk/projects/eprints-uk/docs/simpledc-guidelines/ - RSLP collection description schema
http://www.ukoln.ac.uk/metadata/rslp/ - DecisionSite Analysis Builder
http://www.spotfire.com/products/decision.asp - Dushay, N & Hilman, D. (2003) Analyzing Metadata for Effective Use and Re-Use, DC-2003.
http://www.siderean.com/dc2003/501_Paper24.pdf - Arkive Project
http://www.arkive.org/ - Shabajee, P. (2003). The ARKive-ERA (Educational Repurposing of Assets) project: lessons and thoughts. Semantic Web for scientific and cultural organisations: results of some early experiments, Florence, Italy, 16-17th June 2003.
http://galileo.imss.firenze.it/mesmuses/shabajee_musmuse s.pdf - TARDis
http://tardis.eprints.org/ - EPrints software
http://software.eprints.org/
Author Details
Title: “Improving the Quality of Metadata in Eprint Archives”
Author: Marieke Guy, Andy Powell
Publication Date: 30-January-2004
Publication: Ariadne Issue 38
Originating URL: http://www.ariadne.ac.uk/issue38/guy/