Cashing in on Caching
The Internet is obviously the current buzzword in many organisations and libraries are no exception. Academic libraries have long valued online access to their OPACs and the ability to provide search services of large scale remote databases. However the phenomenal growth in the World Wide Web (WWW) and the demands from an increasing number of people to get easy access to the wealth of information now available has meant that library network provisions are currently undergoing a rapid period of evolution. Even in the underfunded UK public libraries there is a growing interest in public access Internet provision, with a number of public libraries experimenting with a variety of access models.
This growth in both services available and demand to use those services poses many problems for the librarians, systems and networking staff. Not least of these problems is providing a sufficiently responsive service to meet the expectations of the user community. Those readers that have ever tried to retrieve an HTML document from the other side of the planet at three o'clock in the afternoon on a working day will know just how slow this can be. The reasons for this performance problem are many fold: not only are you competing for bandwidth on the local library networks but also for bandwidth on the national and international Internet links and also the capacity of the remote server.
Ideally one would like to dimension the network and the machines so that there is always sufficient bandwidth and server capacity available to handle everybody's requests. However this is not practical for both economic and logistical reasons. Instead we must all try to make the most of the facilities that are available. One technique which helps both improve responsiveness for WWW end users and also reduces network loading is caching. This article explains how WWW caching works, why librarians should be looking at it and briefly outlines the software and services that are currently available.
What is Caching?
In the WWW, resources are accessed via a variety of protocols such as the HyperText Transfer Protocol (HTTP), the File Transfer Protocol (FTP) and the Gopher Protocol. The access protocol for a resource can be seen at the start of the Uniform Resource Locator (URL) that is entered and displayed by the Web browser. For example, the URL pointing to the Loughborough University home page, http://www.lut.ac.uk/, has an access protocol of "http" indicating that the HTTP protocol should be used. For the vast majority of protocols, the browser opens a connection directly to the remote server using the specified access protocol in order to retrieve the resource. Protocols, in case you're wondering, are the mini-languages that computer programs use to talk to each other over the network. HTTP is the most popular one on the Internet at the moment due to its popularity as a transport mechanism for HTML pages in the World-Wide Web.
The basic idea behind caching is to keep copies of the things which have recently been looked at. Caching techniques are used at all levels of modern computer systems, but are a comparative late-comer to the Web. On the Web, caching typically involves the browser itself remembering the objects which were returned when URLs were looked up, by storing them on disk and in memory, and possibly sending its requests via a cache server rather than using them to directly access the remote server. Cache servers are a particularly useful concept, because they allow large numbers of users to share a pool of cached objects.
The cache server takes the URL requested by the Web browser and examines a database of local copies of resources that it has already seen. If the resource with the given URL is held in this database, the cache server returns its local copy of the resource straight back to the browser. If not, it uses the URL to retrieve the resource from the remote server, passes one copy of the resource to the end user's browser and enters another copy of the resource into its database. This copy in the database can then be used to locally satisfy requests for the same resource from other local cache aware Web browsers. In practice, things are slightly more complicated, in particular because of the need to consider when an object in the cache is out of date.
Most Web browsers now come with good support for cache servers via HTTP proxy mode. The common graphical browsers often have dialogue boxes such as the one from NCSA's X Mosaic shown in Figure 1 below, which make the entry of this information easy. Alternatively some platforms allow Web browsers to pick up their proxy information from environment settings or external files which can be configured by systems staff and then made available to all workstations in a cluster, or an organisation. Also note that many browsers allow a list of machines and/or domains which are not to be proxied to be entered. This is useful for allowing access to local Web servers without having to go through the local cache server.
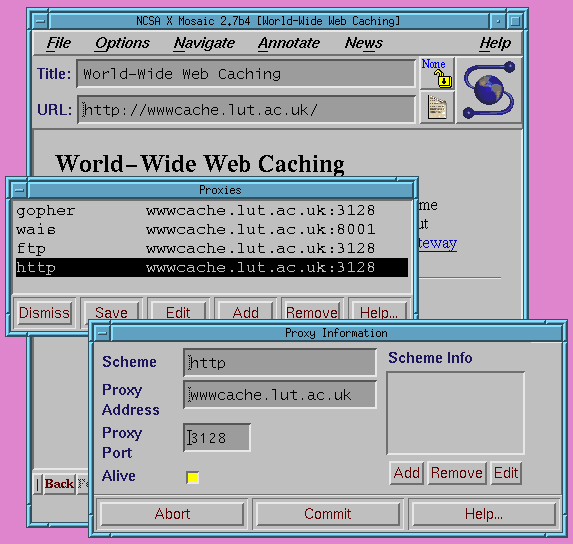
Figure 1: The proxy configuration dialogue from X Mosaic
The basic model of caching works well for static documents that never change. However there are now many parts of the WWW that consist of dynamic or short lived documents. The presence of these types of resources has resulted in the development of more sophisticated caching policies that allow browsers and proxy servers to determine how long local copies of cached resources should be kept. Some resources can never be cached - such as most Common Gateway Interface (CGI) programs that are used to query databases and provide processing for forms. It has to be assumed that the objects these return may be different every time. The end users will usually be unaware of the sometimes quite complex decisions that the Web browser and proxy server will make on their behalf to deal with these situations. The only noticeable effect to the end users should be that access times to most, but not all, resources are dramatically reduced by the use of caching.
We should note in passing that Web page developers may defeat most caching schemes by making extensive use of uncachable resources such as CGI programs. Whilst this might seem desirable for some reasons, such as the gathering of authoritative statistics on server hits, developers should bear in mind the impact that this approach has both on the network and on the machines which serve up these resources. If there is a bottom line, it's that the Web is evolving towards an architecture which will be totally dependent upon caching, and you cannot count on being able to gather truly accurate statistics. So - get used to it!
To really work effectively, caching should ideally take place over a relatively large population of users. This is so that the chance of two or more users requesting the same resource which can then be return at least once from the local cache is increased. However, the more users that a cache server has, the bigger the machine that will be need to host it. Also the cache server that the Web browser contacts should be kept as local to the end user as possible - ideally within the local area network of the organisation - so as to not flood expensive or low bandwidth long distance links with traffic from the Web browsers. This appears to be a dichotomy - on the one hand we want to cache for as many users as possible but on the other hand we don't want to have to buy a massive machine to act as the cache server and also we'd like to locate it as near to the users as possible.
To overcome this problem, the idea of cache meshes is gaining popularity (see figure 2). Conceptually this is very simple - the Web browser on the users desktop machine has a small disk cache to keep local copies of resources that just that machine has accessed. The browser is configured to talk to a local cache server running on a relatively small machine that caches resources for all the browsers within the organisation. This cache server in turn can refer to similar neighbouring caches in the network and also to very much more powerful regional and/or national cache servers which are located close to the physical network boundaries between Internet Service Providers and/or countries. International Internet connections tend to be very expensive!
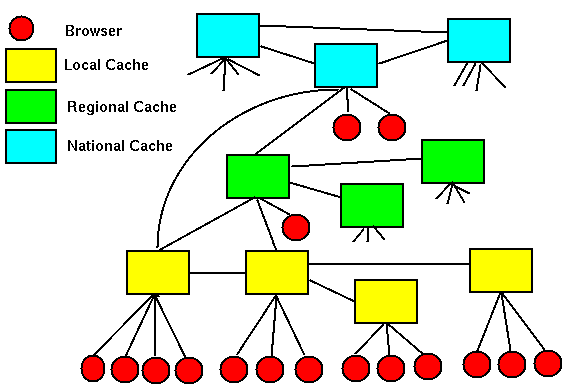
Figure 2: One possible layout for a cache mesh.
In the cache mesh model, when the user presents the browser with a URL (or follows a hyperlink), the browser firstly checks its local disk cache. If the requested URL is not found there, the browser uses proxy HTTP to ask the local cache server for it. If the local cache server has a cached copy it returns it immediately, otherwise it asks its neighbouring caches if they have a copy of the resource. If none of them do, it asks its parent cache or caches. If the parents don't have a copy, the remote server finally gets asked for the resource. Incidentally, most of the efforts to build meshes of cache servers are using yet another protocol - the Internet Cache Protocol invented by the Harvest project at the University of Colorado.
This approach may sound long winded but the delay in doing the whole operation is negligible compared to the delays experienced in satisfying trans-oceanic and trans-continental Web requests. If possible, a copy of the returned resource is cached in the parent regional or national cache, the local organisational cache server and the browsers disk cache, so that future accesses to the resource will be much faster. Note that sometimes cache meshes are refered to as cache hierarchies. However as shown in the figure, browsers and cache servers can connect in at any height; some people have their desktop browser configured to use HENSA's UK National cache for example. Therefore they are not strictly hierarchies in practice.
Why should libraries need to know about caching?
There are a number of reasons why libraries with Internet access and public Web browsers should be interested in caching. The first one is that it will improve the perceived response speed of the WWW for their end users, especially if lots of the users are accessing the same sets of pages over and over again. As "keeping the punters happy" is always a good policy in a library, this would appear to be a very important benefit!
Caching also reduces the amount of communication traffic between the organisation's local area network and other machines in the Internet. This is helpful for two reasons. Firstly, for all types of library site, be they academic, commercial or public, the Internet links that they have will appear to be able to handle the demands of the browser users better and may remove the need to upgrade the bandwidth capacity of the link. For libraries that actually pay real money to send and receive bytes on their Internet connections (which discounts many of the academic libraries with their block funded JANET/SuperJANET connections but applies to many commercial libraries) the possible reduction in network traffic due to caching could equate to a saving in real money.
For example, imagine that a library has a 128kbps ISDN connection to the Internet that is charged for by the second. Also assume that it call costs are about 5p per minute (which is roughly right for a daytime local area call). Now if there are 10 Web browsers and on average their users each generate 1MB of network traffic per hour from 9am to 6pm, then the total amount of traffic per day would be 90MB. This would take 5898.24 seconds of connect time to transmit and would cost thus cost at least £4.92 per day without the use of a cache. This gives a quarterly call cost of a little under £300 for this single line.
Now imagine that the Web browser traffic from the ten browsers goes through a cache server and that 20% of the requests can be satisfied from a locally cached copy. Looking at this simplistically, this could mean that on average 20% of the connect time to the ISP is no longer required and thus the quarterly bill would be cut to £240.
Let us now see what happens if we decide to be radical and have 50 Web browsers running in the library, each of which is still producing an average of 1MB of network traffic per hour. This would give rise to an average bandwidth usage without a cache of around 117kbps - very close to the raw line speed of 128kbps. This means that without a cache, the ISDN connection to the Internet would be swamped with traffic, particularly since the overhead in running an Internet connection over the ISDN is not considered! With a proxy cache server in place and an average hit ratio of 20%, the bandwidth demand would on average be reduced to around 93kbps which results in less likelihood of congestion for the Internet link. The call costs (which would now be much higher per quarter) would still be reduced by an average of around 20%.
There is of course a point below which a local cache server is uneconomic. If there are only a few machines that can access the Web from a site and/or the users are likely to always be retrieving very diverse resources from the Web, the cache's hit ratio will be low and the amount of bandwidth saved will not justify the expense of having the cache server. In this case, it is advisable to have a large per-browser cache, and to take advantage of any cache server offering of your Internet Service Provider and/or any sites running cache servers which are "nearby" in network terms.
Whether a particular site will benefit from having a cache server is a call that only the staff at that site can make of course - only they know what resources they have and what their users are likely to be using the Web for. However, as a data point, here at Loughborough University the cache hit ratio is typically over 40 percent, which represents a significant saving on bandwidth usage on our SuperJANET link and improved response times for our users. It also means that we're being "good network citizens", as a large fraction of that traffic that we didn't generate would have been going across the already heavily overloaded international connections in the Internet.
There is a last reason that librarians should be aware of Web caching - if the library is part of a larger organisation (a company or university for example) that makes a strategic decision to deploy Web caching across all of its machines, there may be some copyright and licensing implications. These arise because the cache is effectively making an automatic local copy of a resource. At the moment, this mechanism is treated as part of the operation of the network infrastructure by most information providers. Whilst most of the information being gathered from the Web is provided free of charge (even if still under copyright), this does not cause a problem. However as commercial publishers are now trying to shoehorn existing paper and CD-ROM based subscription services onto the Web, there are likely to be an increasing number of sites that can only be got at using some form of access control. These are typically used to determine whether or not to return a resource, and sometimes even what type of resource to send.
The only universally applicable form of access control which is available for the Web is restriction by Internet address. This is a very weak approach and in addition to the ease with which it can be spoofed, is liable to being broken when cache servers work together in meshes. On the other hand, it is simple for both publishers and librarians/site network managers to use as it usually just requires the site to give the publisher a set or range of addresses for the machines that should be able to access the service. The danger comes if the cache server is included in this range and the user's browsers are configured to use the cache for the publisher's Web server. Requests for resources from this commercial publisher from local Web browsers will cause a local copy to be cached. This can then be accessed both from other local browsers and also from other sites which have caches that can talk to the local cache server. It is mainly the latter that needs the most careful attention as it means that third parties can access some of the commercial publishers resources through the local site without paying the subscription fees. This is obviously something that librarians are ideally placed to advise upon and monitor.
In this simple case, browsers should simply be configured not to use the cache server when talking to the publisher's Web server, and the publisher should be told to refuse requests from the cache server. More complex scenarios exis t, however, and more effective forms of access control also exist. The most effective mechanism is probably encryption of the communication between the browser and the Web server. This turns the whole Web session into a code which cannot readily be deciphered. Encryption has been widely deployed in the form of Netscape's Secure Sockets Layer (SSL) protocol. This forms a "secure" communications link over which HTTP, for example, can be spoken. Unfortunately, the version of SSL which has been put into Netscape's Navigator Web browser has been crippled in order to satisfy the US secret services - who object to people using codes which they cannot decode! This is unfortunate, to say the least, since the nature of the changes means that the encrypted messages sent by Netscape Navigator can readily be decoded by anyone who is sufficiently interested and has a moderate amount of computing power available. Ultimately this end-to-end encryption is the most effective way for publishers to protect their intellectual property, but interference from the likes of government spying organizations and politicians is hindering its use.
Documentation and Software Available
Now that you are all hopefully sold on the idea of Web caching, what resources are available to help you find out more? We've tried to gather some information about caching at Loughborough University, and you may find these pages a good place to start. This includes details of the current Web caching activity on JANET, as well as pointers to software, setting up cache meshes, and some info on the international caching scene.
Other good places to look for information about Web caching are the HENSA/Unix team's collection of Web caching related material, and the National Laboratory for Applied Network Research site on Web caching in the United States. The European Commission DESIRE project recently completed a comprehensive study on Web caching technology, which is also well worth checking out.
If you are interested in all of the gory technical details of how caching and proxy servers work, which have been somewhat glossed over in this article, then check out the W3 Consortium proxy documentation. This explains all about the techniques used by proxy cache servers, why some documents are uncachable and how cache servers determine if a document is stale or not. If you are a techie and you're contemplating running a cache server, you might want to join one of the many caching related mailing lists. There are too many to document them all here, but a couple which might be of interest to UK folk are the cybercache mailing list in Loughborough, and the wwwcache-admin and wwwcache-users mailing lists at Mailbase. The cybercache list is primarily for UK related caching discussions. It also acts as a sort of self-help group for UK people running the Squid (aka Harvest) cache server software. The wwwcache-admin list is specifically for people running local cache servers which are using the HENSA/Unix cache service as their parent, and is run as a closed list. The cybercache list, on the other hand, is an open list which you can join by sending a message with the word subscribe alone in its body to cybercache-request@mrrl.lut.ac.uk. The wwwcache-users is also an open list for general users of HENSA's JISC funded National Cache. NB: these lists can be very techie!
Conclusions
This article has hopefully provided a brief introduction to the concept of Web caching. Whilst it is not claimed that caching will be beneficial for absolutely everyone, many sites will find that Web caching provides improved response times from Web browsers and reduces network traffic, both locally and also on the overcrowded international links. It therefore can make users happier, reduce communication infrastructure costs and allow sites to be "good network citizens". It is hoped this is article may pique the interest of librarians and computer centres at sites not currently running Web caches, and also draw attention to its presence and implications to librarians at those sites that do already employ it. Web caching is a technology whose time has come!