What Are Your Terms?
The JISC Information Environment Metadata Schema Registry (IEMSR) Project [1] is funded by JISC through its Shared Services Programme to develop a metadata schema registry as a pilot shared service for the JISC Information Environment (JISC IE). Partners in the project are UKOLN, University of Bath and the Institute for Learning and Research Technology (ILRT), University of Bristol. The Centre for Educational Technology Interoperability Standards (CETIS) and the British Educational Communications and Technology Agency (Becta) are contributing to the project in an advisory capacity.
This article describes the work of the IEMSR Project to date against the background of metadata usage by applications within the JISC IE. It describes the tools that the project is developing, and highlights some of the issues, both technical and policy-related, that the project is considering.
Metadata Schema Registries
A metadata schema registry is an application that provides services based on information about 'metadata terms' and about related resources. The term 'metadata term' is used here to denote some identified 'unit of meaning' deployed in a metadata description. The label 'term' is preferred here to 'element' or 'data element' as it is intended to encompass several different types of component that occur within metadata descriptions, both in the 'attribute space' and the 'value space', the 'elements', but also the 'schemes' that provide values for those elements. Such 'terms' are typically defined and managed as functional aggregations created to support some operation or service.
The services offered by a metadata schema registry may cover many different functions, and different metadata schema registries may provide different sets of functions depending on their purpose, scope and context; those functions might include:
- Disclosure/discovery of information about metadata terms
- Disclosure/discovery of relationships between metadata terms
- Mapping or inferencing services based on relationships between terms
- Verification of the provenance or status of metadata terms
- Disclosure/discovery of related resources (such as functional aggregations of terms, guidelines for use, bindings for metadata instances, etc)
The Dublin Core Metadata Initiative (DCMI) maintains a metadata schema registry that offers services based solely on the descriptions of the terms within the metadata vocabularies maintained by DCMI [2]. A Web site provides a human-readable interface to the registry, and simple REST- (Representational State Transfer) and SOAP- (Simple Object Access Protocol) based APIs support a few basic operations that return machine-readable descriptions of terms.
In the UK, the Metadata for Education Group (MEG) Registry Project [3], funded jointly by JISC and Becta, sought to build on the work of the DESIRE and SCHEMAS projects to develop a schema registry for the educational metadata community. The work was developed further by the EU-funded CORES Project [4]. The MEG Registry and CORES projects essentially extended the data model deployed within the DCMI Registry to include the concept of the 'metadata application profile'.
Metadata Standards and Metadata Application Profiles
Research within the DESIRE Project [5] explored the way implementers deployed metadata standards, and the project indicated that the concept of 'profiling' might be applied to metadata standards, similarly to the ways it was applied in other contexts. The notion of the metadata 'application profile' was introduced to a wider audience through the paper by Rachel Heery and Manjula Patel, "Application profiles: mixing and matching metadata schemas" [6].
Heery and Patel contrast the 'top-down' approach of standards makers concerned with generality and interoperability, and the pragmatism of implementers requiring specificity and localisation who optimise standards for the context of their application. The paper proposes a typology of metadata schemas in which:
- namespace schemas declare (name and define) data elements;
- application profiles describe the use of (previously declared) data elements to meet the requirements of a particular context or application.
A metadata application profile may
- select elements from multiple namespaces (but must not use elements that are not previously declared in a namespace schema);
- refine the definitions of elements by making them narrower or more specific;
- specify constraints on the permitted values of elements by mandating the use of particular controlled vocabularies or formats
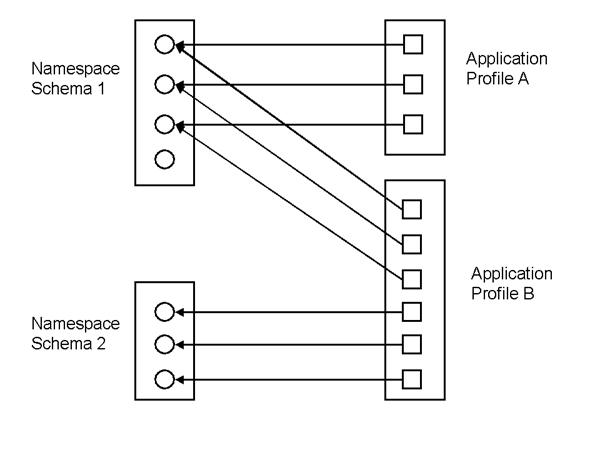
Figure 1: Application Profiles and 'Namespace Schemas': a simplified view
Given this principle that a metadata application references, or 'uses', existing data elements, it is often the case that the development of an application profile is accompanied by the development of a new set of data elements to provide the descriptive capability required to supplement that of the standard schema: that is, a new 'namespace schema' is supplied by the developers of the profile.
For example:
- 'Simple Dublin Core' is an application profile of the Dublin Core (DC) metadata standard in which metadata descriptions make use of the 15 elements of the Dublin Core Metadata Element Set, and all elements are optional and repeatable [7] [8]. The Simple Dublin Core profile has been widely implemented, particularly by adopters of the Open Archives Initiative Protocol for Metadata Harvesting (OAI PMH) [9], where it has been applied to the description of many different types of resources. (The "oai_dc" metadata format, which the protocol requires data providers to support, is a serialisation of the Simple Dublin Core metadata application profile.)
- the RSLP Collection Description Schema [10] specifies how terms drawn from the three Dublin Core 'namespaces' and from other metadata vocabularies, including a vocabulary constructed for this purpose, are used together for the description of a collection, its location and agents related to the collection and location. It makes recommendations for constraining the value space of terms (in the form of 'encoding schemes' and human-readable guidelines) and for the obligation to use terms in a description.
Implementers of both the Dublin Core and the IEEE Learning Object Metadata (LOM) [11] standard recognise the principles of modularity (the notion that component parts of metadata standards may be (re)used as 'building blocks' in different contexts) and extensibility (the capacity to introduce new components as required to meet functional requirements not catered for by the standard). They regard the metadata application profile as a key mechanism for realising these principles [12].
Metadata in the JISC Information Environment
The JISC IE is a 'set of networked services that allows people to discover, access, use and publish' information resources within the UK HE and FE community [13]. The JISC IE is not itself a single system or service; rather, it is an open and expanding collection of services that can be used in combination as components to deliver functionality of interest to a user. Many of the functions provided by service components within the IE depend on operations on metadata records describing those information resources, and the effective transfer of metadata records between service components is a critical factor in their interoperability.
To support the core functions of discovery of, and access to, information resources, the JISC IE Technical Architecture [14] specifies several mechanisms by which one service component can make metadata available to other service components. The Standards Framework for the JISC IE [15] specifies a set of protocols that implement these mechanisms and also the formats in which metadata records should be made available. This metadata is based on Dublin Core and the LOM standard. More precisely, the Standards Framework recommends the deployment of two application profiles of these standards: Simple Dublin Core (as described above) and the UK LOM Core [16], a profile of the LOM designed to support the disclosure and discovery of, and access to, learning objects designed for use at any educational level within the UK. Records conforming to these profiles, serialised using the recommended formats or bindings, form a 'baseline' for the transfer and exchange of metadata between service components in the IE.
If metadata interoperability within the JISC IE is based on these two application profiles and their associated formats, what then is the role for a metadata schema registry? Is it not sufficient to direct implementers to the sources of information about these two profiles and the corresponding formats provided by their owners?
In addition to supporting these 'baseline' metadata application profiles, some content providers within the JISC IE seek to enable a richer level of functionality by developing additional application profiles and, where necessary, additional metadata formats for the serialisation of descriptions based on those profiles. Typically the sharing of such richer/extended metadata takes place between a closed (or semi-closed) group of service providers and depends on prior co-ordination between the partners on the use of metadata terms and, if necessary, on extensions to syntactical bindings. For example:
- The 'RDN DC' Dublin Core Application Profile is used for the sharing of metadata records between hubs within the Resource Discovery Network [17][18]
- The RDN/LTSN LOM Application Profile (RLLOMAP) was developed to support the sharing of metadata records between RDN hubs and the former Learning and Teaching Support Network (LTSN) Centres (now Higher Education Academy Subject Centres) [19][20]
Disclosure, Reuse, Provenance and Relationships
As the number of metadata application profiles deployed increases it becomes important to have a means by which the developers of those profiles can disclose their existence, and by which other parties can discover them.
Those other parties may be the developers of applications that are interacting with the services using those metadata application profiles. They may also be the developers of quite separate services seeking to build on existing practice. That 'reuse' may take the form of adopting an existing profile as a whole, but it may involve constructing a new profile that references a new permutation of existing terms. It may be the case that the developer of a new service finds that it is not appropriate to adopt an existing application profile in its entirety, but that a profile references, say, controlled vocabularies, that are indeed suitable for their purposes.
Clearly if the developers of new services are to be encouraged to adopt existing metadata application profiles and to reuse existing 'terms' as components within their own application profiles, then it is important that the descriptions of these resources not only provide clear explanation of the meaning and use of the terms but also include clear indications of their status and provenance. Knowing whether a term or set of terms is stable or whether it is still the subject of testing and development may condition decisions about its suitability for reuse. Similarly being able to establish that a term has been deployed in multiple application profiles may give some indication of its usefulness.
New metadata terms are typically created in order to express some new piece of information for which no existing term sufficed. However, it is common that the description or declaration of a metadata term includes a description of relationships between the new term and one or more existing metadata terms. While the description of these relationships in isolation is useful, the aggregation of this information about multiple terms provides a basis for more powerful mapping or inferencing operations to be developed.
These, then, are some of the factors motivating the investigation of the development of a metadata schema registry for the JISC IE.
Where these discovery functions are provided to a human user, strictly speaking, within the high-level functional classification of the JISC IE Technical Architecture, they are provided by a presentational service that mediates between the user and the metadata schema registry itself, a service characterised as a 'metadata portal' in the diagram below:
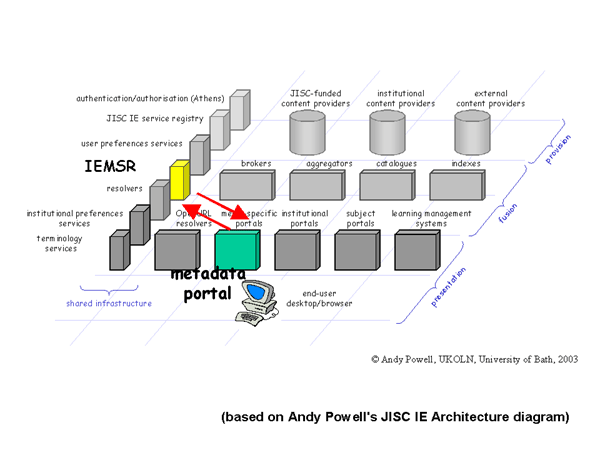
Figure 2: A 'Metadata Portal' queries the IEMSR
However, increasingly the 'agents' requiring information about metadata terms are not only human beings, but also software applications performing operations on behalf of those human beings. It is expected that components within any of the four JISC IE functional categories - content providers, fusion services, presentation service, or other shared services - might interact with the IEMSR to provide or obtain information about metadata terms.
For example, a presentation service might obtain a set of human-readable labels to apply in the display of the content of a metadata record; a metadata creation tool might use the description of an application profile to load appropriate controlled vocabularies or 'tool tips'; and a fusion service might make use of information about equivalence or other relationships between metadata terms.
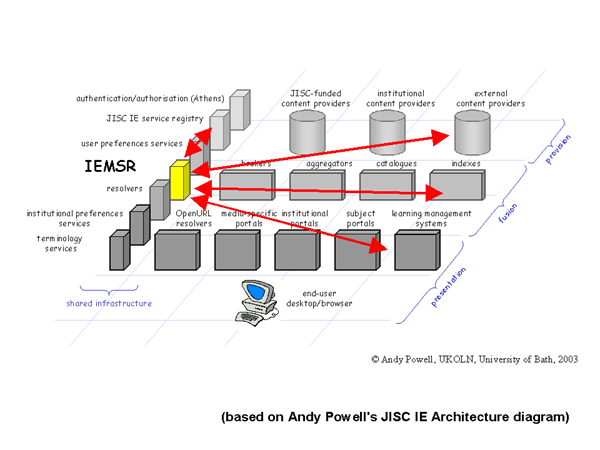
Figure 3: The IEMSR and other IE components
Metadata Application Profiles and Metadata Formats
An important note of qualification is required here: a metadata application profile, at least as it has been defined within the context of the IEMSR, does not in itself describe how to represent a metadata instance conforming to that profile in a machine-readable form. An application profile is (only) an 'information model'. To represent an instance of that model, a binding is required - a mapping between the components of that information model and the structural components of a machine-readable syntax, typically, in the case of the JISC IE at least, XML. Indeed the relationship between metadata application profile and metadata format is one-to-many: metadata descriptions conforming to a single metadata application profile may be serialised in several different formats.
In its present form, the IEMSR does not describe these mappings, and it requires that applications using the IEMSR have built-in information about such mappings if they are to use the data made available by the IEMSR in operations on metadata records.
The Trouble with Terms and the Matter of 'Meta-models'
Central to the concept of the metadata application profile is the notion that components defined in a 'namespace schema' can be brought together in the new context of the metadata application profile and then deployed in metadata descriptions based on that profile. However, the experience of designing metadata application profiles and of developing applications that work with both DC and LOM metadata has suggested that the concept of 'mixing and matching' requires some qualification.
The reason for this is that the 'terms' defined by metadata standards are defined within the context of conceptual frameworks or 'meta-models' which determine how those terms are to be interpreted. And different metadata standards do not necessarily adopt the same, or even compatible, meta-models.
A recent DCMI recommendation, the DCMI Abstract Model (DCAM) [21], seeks to articulate the meta-model for Dublin Core. Essentially, the DCAM presents a Dublin Core metadata description as a set of statements about a single resource. In its simplest form, each statement consists of a reference to a 'property' and a reference to a second resource, which the DCAM calls a 'value'. That is, each statement asserts the existence of a relationship between two resources, and the type of relationship is indicated by the property. All DC elements and element refinements are properties, i.e. they are types of relationship that may exist between two resources. A reference to a property in a statement is treated as if it is always a reference to the same concept, the relationship type.
The LOM standard does not explicitly describe or refer to a meta-model, but it defines the structure of a LOM metadata instance in terms of a set of LOM data elements organised into a tree or nested container structure. LOM data elements, then, are quite different in nature from Dublin Core elements: they are containers for sequences of other LOM data elements, or for values, and the nature of the values is specified by the datatyping rules of the LOM standard. LOM data elements are interpreted in the context of the other LOM data elements within which they are contained.
The consequences of this are that, firstly, a full mapping between the two metadata standards is not straightforward (because the mapping process must take into account the differences in the meta-models), and secondly, terms defined within the two meta-models are different types of resource and can not be directly combined. (Note: It is beyond the scope of this article to present a detailed discussion of the DC and LOM meta-models. Accounts can be found in the work of Mikael Nilsson and his colleagues on the development of a (Dublin Core-compatible) RDF binding for the LOM standard [22]).
Furthermore, the two different conceptual frameworks result in slightly different approaches to the metadata application profile. The terms referenced by a Dublin Core application profile are terms of the type described by the Abstract Model, i.e. an application profile describes, for some class of metadata descriptions, which properties are referenced in statements and how the use of those properties may be constrained by, for example, specifying the use of vocabulary and syntax encoding schemes.
An examination of existing LOM application profiles reveals a different approach:
CanCore can be seen to take its cue from a definition of application profiles that precedes ones more recently referenced. Instead of "mixing and matching" elements from multiple schemas and namespaces (Heery & Patel 2000), it presents "customisation" of a single "standard" to address the specific needs of "particular communities of implementers with common applications requirements .." [23]
That is, a LOM application profile is designed within the LOM tree/container framework and describes how the information model described by the LOM standard is adopted to the requirements of an application.
For the IEMSR Project, the incompatibility of the LOM and DC meta-models has presented the challenge of managing descriptions of two distinct sets of resources - Dublin Core Application Profiles and the components that they reference on the one hand, and LOM Application Profiles and the components that they reference on the other - and doing so, as far as possible, within a common set of software tools.
The IEMSR Architecture and the IEMSR Tools
The IEMSR has been developed as an application of the Resource Description Framework (RDF) [24], a W3C recommendation (or rather set of recommendations) for a language to represent information about resources. One of the reasons for using an RDF-based approach is that it facilitates the aggregation of independently created data sources: in particular it means that the IEMSR can take advantage of the availability of existing descriptions of metadata vocabularies created by the owners of those vocabularies using the RDF Vocabulary Description Language (RDF Schema) [25], and published on the Web. And conversely, the descriptions of metadata vocabularies created using IEMSR tools may be made available to other RDF/RDFS applications, either through the services of the IEMSR itself or through the publication of the documents on the Web independently of the IEMSR.
Although this article has tended to refer to 'the IEMSR' or 'the registry' as a single entity, the discussion above noted that a presentation service was distinct from the registry itself, and the project has developed a number of distinct functional components:
- The registry server
- A Web site
- A data creation tool
The IEMSR tools will be made available as open-source software. Both the Web site and the data creation tool act as clients to the registry server. In principle, any of these components could be replaced by another application performing the same function: other parties could develop data creation tools or Web sites to interact with the IEMSR registry server.
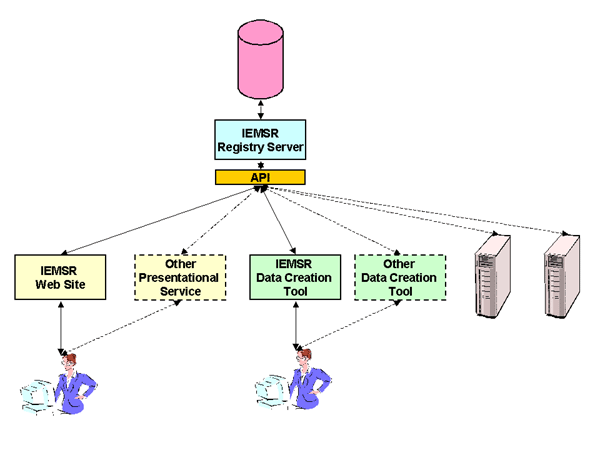
Figure 4: The IEMSR Architecture
The Registry Server
The registry itself is what the JISC IE Technical Architecture describes as a 'shared infrastructural service': it provides interfaces to other applications, but it is largely 'invisible' to the human user of those applications. The registry is an RDF application currently based on the Redland RDF Toolkit. It provides a persistent data store (using a MySQL database) and a REST API for uploading data to the data store and for querying its content. The query interface supports SPARQL [26] the RDF query language under development by the W3C RDF Data Access Working Group.
The IEMSR Web site
The IEMSR Web site is a presentational service. It provides a 'metadata portal' function: it allows a human user to browse and query the data that is made available by the IEMSR registry server - it offers 'read-only' access to the registry server.
One of the challenges has been to present the descriptions of Dublin Core and LOM application profiles through a single interface in a way which emphasises the significant differences between different types of resource but does not present the user with a confusing number of navigation options while they are navigating the data. The current design adopts a 'tabbed browsing' approach, where the user selects a tab as an entry point to a section of the dataset (e.g. Dublin Core and Dublin Core application profiles or LOM and LOM application profiles), and then is presented with the navigation options appropriate to that particular section.
A further challenge is selecting an appropriate 'structural granularity' for the display of application profiles. They are complex objects, and the internal data model of the registry represents a single application profile as a large set of related resources. While this enables rich operations on the data and flexibility in its presentation, a compromise must be found between, on the one hand, presenting a rather overwhelming amount of data to the user in one display, and on the other, presenting a large number of hyperlinked pages in which it can become difficult to maintain a sense of the relationships between the parts and the whole.
At present, the functions provided by the IEMSR Web site are based solely on data made available by the IEMSR registry server. However, user requirements indicate the possibility that it may be necessary to combine data made available by the IEMSR with data drawn from other sources. For example, if it is required to present information about the services which have deployed metadata application profiles and formats, then it may be that that requires a combination of data made available by the IEMSR with data made available by the Information Environment Service Registry (IESR) [27] and/or by other service registries. In the future, it is quite likely that close integration with terminology services may be required.
The Data Creation Tool
The IEMSR Data Creation tool supports the creation of RDF data sources for submission to the registry server. It is written in Java and uses the Eclipse SWT and JFace libraries to provide a natural interface across different platforms.
Although it was noted above that a DC application profile and a LOM application profile are different types of resource, the models adopted within the IEMSR share the same notion that the application profile references or selects or 'uses' a set of existing terms, and provides information about the use of those terms in a particular context.
The Data Creation Tool reflects this by providing a similar interface for the creation and editing of descriptions of both a DC application profile and a LOM application profile. That interface consists of a form divided into two areas: the right-hand panel provides a view of the 'current document' being edited (typically a description of an application profile), while the left hand panel provides a view of data made available by the registry server. The users submit queries to the server and from the result set select items for 'use' in the application profile that they are constructing or editing.
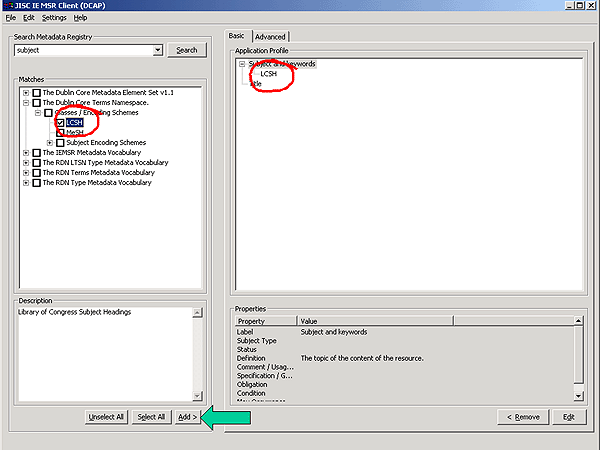
Figure 5: Editing a Dublin Core Application Profile with the IEMSR Data Creation Tool
The figure above shows the editing of a description of a Dublin Core application profile. The registry view (left-hand) panel displays the results of a search on the keyword 'subject': terms matching the query are grouped by the name of the metadata vocabulary within which they are defined. The current document (right-hand) panel displays the components of the application profile that the author is describing. Selected terms from the query result set are added to the application profile using the 'Add' button in the lower centre of the form. Once a reference to a term is added, the author can then provide additional information about the 'usage' of the term in the context of the DC application profile.
A similar mechanism is used for the description of a LOM application profile. The most significant difference is that while in the DC case an open set of properties and classes is available for selection, in the LOM case, the user is presented with a tree-view of the set of LOM data elements prescribed by the LOM standard.
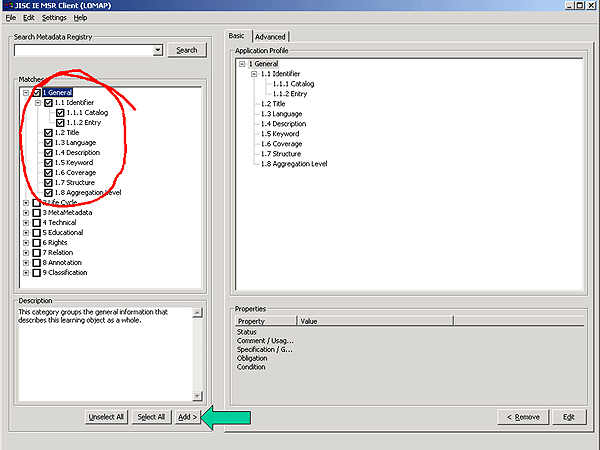
Figure 6: Editing a LOM Application Profile with the IEMSR Data Creation Tool
The Data Creation Tool also enables the user to save their descriptions as a new data source, and also to submit that data source to the registry server.
Challenges for the Future
Centralisation or Distribution of IEMSR Services
The current implementation of the IEMSR might be described as 'semi-distributed'. Where possible, the IEMSR makes use of existing data sources, published on the Web in standard formats by the owners of metadata vocabularies. That data is used by many different applications, including other metadata schema registries, and responsibility for the security and availability of those data sources, and the maintenance of their content, lies with their owners/publishers, rather than with the providers of the IEMSR.
The data sources created using the IEMSR data creation tool described above may also be stored, published and accessed independently of the IEMSR.
The IEMSR serves as one point of access to that distributed data. However, in terms of the services provided across this aggregated data, the IEMSR displays a more 'centralised' aspect. The IEMSR registry server is a single point of access to those services provided on the aggregated data - and also a single point of failure. Future work may include investigation of the appropriate balance between the distribution and centralisation of registry services and the data on which those services are built, and the technologies required to support the choices that are made.
'Collection Policy' and Coverage
The 'boundaries' of the JISC Information Environment, if such boundaries can be said to exist, are shifting and porous: the range of information resources used, and the range of metadata schemas and formats used to describe those resources, are constantly changing. So the questions of what range of data should be exposed by the IEMSR, and how that data can be quality-assured, are important.
The question of persistence of access must also be considered: in a distributed or semi-distributed environment, data sources may become unavailable. It may be necessary to implement a process in which the IEMSR maintains permanent copies of this distributed data in order to guard against that eventuality.
'Meta-models' and IEMSR Scalability
The differences between the DC and LOM meta-models mean that the IEMSR has to manage two quite different sets of information. The 'statement-oriented' DC meta-model is closely aligned with that of RDF, and makes use of RDF Schema (though it does introduce some record/document-oriented aspects which do not reflect RDF's 'open-world' assumptions). However, the way LOM application profiles are described for IEMSR reflects the 'document-oriented' nature of the LOM conceptual model, and is specific to that model. This does raise questions about the scalability of the current approach: extending the coverage of the registry to a new document-oriented metadata standard based on a different document structure, with different constraints on what consisted of an 'application profile', would require additional development effort.
Conclusions
The IEMSR Project hopes that the deployment of a metadata schema registry will contribute to improving the disclosure and discovery of information about metadata terms and the functional aggregations in which those terms are deployed. In highlighting some of the issues raised, the project also seeks to contribute to wider discussions on the use of metadata within the JISC Information Environment and beyond.
References
- JISC Information Environment Metadata Schema Registry (IEMSR) Project http://www.ukoln.ac.uk/projects/iemsr/
- The Dublin Core Metadata Registry http://dublincore.org/dcregistry/
- MEG Registry Project http://www.ukoln.ac.uk/metadata/education/regproj/
- CORES Project http://www.cores-eu.net/
- DESIRE: Development of a European Service for Information on Research and Education http://www.desire.org/
- Heery, R. and Patel, M., "Application Profiles: mixing and matching metadata schemas", Ariadne 25, September 2000 http://www.ariadne.ac.uk/issue25/app-profiles/
- Dublin Core Metadata Element Set, Version 1.1: Reference Description http://dublincore.org/documents/dces/
- DCMI Metadata Terms http://dublincore.org/documents/dcmi-terms/
- The Open Archives Initiative Protocol for Metadata Harvesting. Version 2.0 http://www.openarchives.org/OAI/openarchivesprotocol.html
- RSLP Collection Description Schema http://www.ukoln.ac.uk/metadata/rslp/schema/
- IEEE Standard for Learning Object Metadata http://ltsc.ieee.org/wg12/par1484-12-1.html
- Duval, E., Hodgins, W., Sutton, S., & Weibel, S.L., "Metadata Principles and Practicalities". D-Lib, Vol 8 No 4 (April 2002) http://www.dlib.org/dlib/april02/weibel/04weibel.html
- JISC Information Environment Architecture: General FAQ
http://www.ukoln.ac.uk/distributed-systems/jisc-ie/arch/faq/general/ - Powell, A., Lyon, L., The DNER Technical Architecture: Scoping the Information Environment http://www.ukoln.ac.uk/distributed-systems/jisc-ie/arch/dner-arch.html
- JISC Information Environment Architecture: Standards Framework. Version 1.1 http://www.ukoln.ac.uk/distributed-systems/jisc-ie/arch/standards/
- UK Learning Object Metadata Core http://www.ukoln.ac.uk/metadata/education/uklomcore/
- Day, M. and Cliff, P., RDN Cataloguing Guidelines. Version 1.1 http://www.rdn.ac.uk/publications/cat-guide/
- Powell, A., RDN OAI rdn_dc XML schema(s) http://www.rdn.ac.uk/oai/rdn_dc/
- Powell, A., RDN/LTSN LOM application profile. Version 1.0 http://www.rdn.ac.uk/publications/rdn-ltsn/ap/
- Powell, A. and Barker, P., "RDN/LTSN Partnerships: Learning resource discovery based on the LOM and the OAI-PMH", Ariadne 39, April 2004 http://www.ariadne.ac.uk/issue39/powell/
- Powell, A., Nilsson, M., Naeve, A., & Johnston, P. DCMI Abstract Model, DCMI Recommendation http://dublincore.org/documents/abstract-model/
- Nilsson, M., Palmér, M. and Brase, J. "The LOM RDF binding - principles and implementation". Paper to 3rd Annual Ariadne Conference, 20-21 November 2003, Katholieke Universiteit Leuven, Belgium (November 2003) http://kmr.nada.kth.se/papers/SemanticWeb/LOMRDFBinding-ARIADNE.pdf
- Friesen, N., Mason, J., and Ward, N. "Building Educational Metadata Application Profiles". Proceedings of the International Conference on Dublin Core and Metadata for e-Communities 2002, pp 63-69 http://www.bncf.net/dc2002/program/ft/paper7.pdf
- Resource Description Framework (RDF) http://www.w3.org/RDF/
- Brickley, D. & Guha, R. V., eds. RDF Vocabulary Description Language 1.0: RDF Schema. W3C Recommendation 10 February 2004 http://www.w3.org/TR/rdf-schema/
- Prud'hommeaux, E. & Seaborne, A., eds. SPARQL Query Language for RDF. W3C Working Draft 19 April 2005 http://www.w3.org/TR/2005/WD-rdf-sparql-query-20050419/
- JISC Information Environment Service Registry (IESR) http://www.iesr.ac.uk/