Lessons Learned from Developing and Delivering the BORGES Information Filtering Tool
Although it may appear that it is only recently that we have discovered a need for automatic information filtering, the practice of automatically filtering a flow of information has been in use for over 30 years. The emphasis in systems since the earliest days has been on the speed of the filtering operation, ensuring that it is performed as quickly as possible. Because of the volume of information now being generated and the requirement to have this filtered, issues of quality or the relevance of information filtered for a user, are now becoming increasingly important.
The BORGES project was a research and development project which was partly funded by the European Commission under the Libraries program (project 3052) and ran from January 1995 to July 1996. In BORGES we developed, implemented and evaluated an information filtering service for WWW pages and USENET news. There is a difference between an information filtering service as developed in BORGES and keeping informed about site changes in WWW pages as described in Paul Hollands' recent article in Ariadne. Infomration filtering matches profiles which are expressions of users' fixed information needs against a stream of documents such as USENET news or new or updated pages appearing on the web. The topic addressed in Hollands' article is keeping informed about changes to web pages irrespective of their content and whether they may be of interest to a user.
What made BORGES different from other information filtering projects was that it was user-driven and developed within a library context as a service offered by a University library. The filtering service was offered to a population of users at two University library sites (Dublin City University and Universität Autonoma de Barcelona) and feedback from users as well as log analysis of system use, was used to refine the BORGES system. At the Dublin site the users were from a broad spectrum across all Faculties while in Barcelona the users mostly came from parts of the Arts Faculty. The majority of users were not experienced internet users and would be classified as novices in that regard.
The role of Dublin City University in BORGES was to enhance the functionality of an early version of the information filtering system with some IR techniques which would improve the effectiveness of the service being offered. This was to be done by building upon our previous experiences in experimental IR research and here we present how the results of incorporating our IR research into an operational information filtering system, worked out.
Unlike information retrieval where the entire document collection is available at query time and thus can be used to make statistical estimates of word occurrences, in information filtering we are querying "blind" because we are filtering a new stream of documents, not knowing term distributions except based on samples of previously filtered documents. In BORGES, a number of documents to be filtered are gathered together, either by retrieval by our web robot from WWW sites or from a local USENET news server, and these are indexed by the SMART text retrieval system on a daily basis. Once indexed, normally done overnight, each user profile in the system is used as a query to the newly-gathered database and the top-ranked WWW pages or news articles are used as a digest for that user profile for the next day. In performing document ranking, SMART assigns each term in each user profile a weight or degree of importance based upon its statistical distribution throughout the corpus.
The first version of the BORGES filtering system was operational and made available to users in Dublin in October 1995 and BORGES was operational for less than one year overall. The second version called BORGES V2, with our information retrieval enhancements, was operational in March 1996. Essentially BORGES V2 retained the features introduced in the first version of the system, namely keyword matching between a user's profile or query and the text of USENET News articles or newly found WWW pages. There were approximately 70 registered users of the system in Dublin, and a larger number of users at the Barcelona site.
BORGES users used the system via Netscape or some other WWW interface supporting the same HTML as Netscape 1.1. Each user logged onto the system with their personal username and password and was taken to their personal welcome page. A user is allowed to have any number of profiles or queries and each running of the filtertool (5 times per week normally) matched each profile against the incoming documents to be filtered. In response to this, each profile generated a digest consisting of the top 50 ranked documents from any source (WWW page or USENET news article) which was also stored locally in the case of a news page. This relatively infrequent batching of documents and running against profiles contrasts with the up-to-the-minute response times of other information filtering systems and is so because USENET news postings and new pages on WWW are not necessarily of immediate interest to our user community; knowing about them can wait until tomorrow.
The BORGES filtertool filters all postings to a set of newsgroups and we also have a set of WWW pages that we use to act as "seeds". Every time the filtertool runs, each seed page is retrieved from the web and analysed. Any HTML links from that seed page cause a second set of pages to be retrieved into the filtertool and this process is repeated once again, thus retrieving seeds, their "children" and "grandchildren". In addition to using known, static seed pages such as "What's New" pages, since the start of the project we have also been able to add URL specifications which are actually search specifications broadcast to WWW search engines. These are created manually and added to the list of WWW seeds in response to a user's profile. So, if a user is interested in tennis and tennis championship results, one of our WWW seed pages might be a search to AltaVista or InfoSeek for WWW pages on "tennis+championship+result".
For each of the pages retrieved by our web robot, if the date of last modification of that page is more recent than the last running of the filtertool, then that web page is added to the cache of documents to be indexed and matched against all user profiles for all BORGES users. In addition to web pages, all articles appearing in all newsgroups from a specified list are also filtered and treated, for indexing and filtering purposes, identically to web pages. Initially we filtered over 900 newsgroups but found the sheer number of news articles was drowning the much more limited number of web pages being found and we reduced this number.
When a user logged in to BORGES, he/she could examine the sources of information being filtered (list of newsgroups and WWW seed pages) and is also presented with a list of their profile names. From there a user could view a summary (top 5) of the 50-document digests for each profile, for each day's filtering going back up to 10 days, as shown in Figure 1. This would be done if the user had not logged on to BORGES for some time. The alternative for a regular BORGES user would be to view today's digests, a top-5 summary of the best-matched articles for each of the user's profile
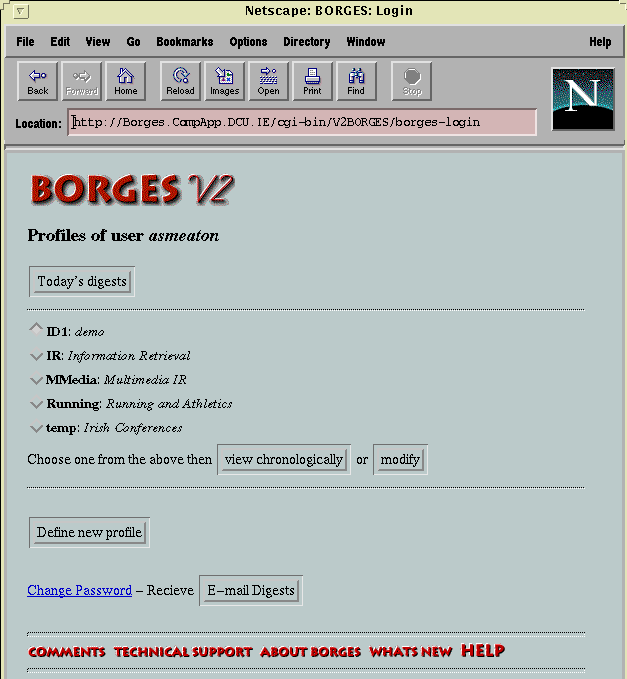
- Figure 1: Personal Digest Screen
Figure 2 shows a sample user modification of a profile, although this could also be the creation of a new profile as the interface is the same. The profile is called "Information Retrieval" and consists of 6 terms. Each of these is actually a phrase rather than a word, as indicated by the "_" character linking the words. By inputting "information_retrieval" as a phrase, this phrase is added to the BORGES phrasal database and for subsequent filtering operations, that phrase, and all phrases in the phrasal database, is identified in documents if it occurs. Thus the user is allowed to augment the single-term vocabulary with multi-word phrases (up to 6 words) of their own definition. In addition to the phrase "information_retrieval" being a searchable indexing term, constituent words of phrases, the words "information" and "retrieval" in this case, are also searched for in document texts. The highest score is given to documents with "information_retrieval", then to documents with the terms "information" and "retrieval" both occurring, then to documents with either, and so on. As we use SMART as the underlying text matching engine, this is done by automatically assigning term weights based on term occurrence frequencies.
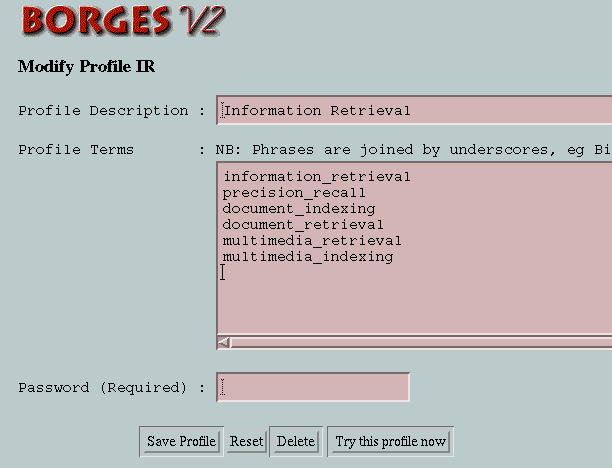
Figure 2: Profile Input / Modification Screen
The handling of phrases is something that has been introduced in V2 of BORGES but there are other features that V2 adds. The most important of these is the manual disambiguation of polysemous query terms/phrases in users' profiles and the user-transparent expansion of profile terms. In BORGES V2 we ask the user to disambiguate any profile terms that have more than one possible semantic interpretation in WordNet [Miller, 1995]. Figure 3 shows a sample disambiguation of the term "information" which, according to WordNet, can be a kind of message or subject matter, a formal accusation of a crime, or knowledge acquired through study or experience. The user is requested to choose whichever of the offered senses apply to the profile in question. If the user chooses none of the offered senses, that term is not expanded with related terms. If the user chooses one or more interpretations, then for each interpretation the user profile is (transparently) expanded by adding in synonyms, "parents" and "children" terms from the hierarchy, albeit with smaller weights than on the original profile term. The weights assigned to these term expansions depend on their relationship to the original profile term and have been determined empirically as part of our experiments in TREC-4 [Smeaton et al., 1996].

Figure 3: Disambiguating the Profile Term "Information"
User's experiences of this disambiguation process have been positive as determined through questionnaires and interviews. We have found that disambiguation of terms actually helps users in formulating their profiles and clarifying their information needs. Profile expansion may also cause the retrieval of documents which would not contain any of the original profile terms but only their expansions and this this has not caused problems with users. In fact we regard this as the "magic" Bruce Croft referred to in his recent article in D-Lib on the most important points for IR system developers to include in their systems [Croft, 1995].
The BORGES project is over and is no longer operational at either the Dublin or Barcelona sites and the interesting question is why not. Involvement in a research and development project like BORGES leads to lessons learned and while some of these are the answers to scientific inquiries such as which IR techniques work best in terms of precision and recall for filtering applications, there are also lessons to be learned from providing and operating such a service. A user-driven project where a service is deployed and its usage analysed generates experiences in both scientific and operational spheres.
Our first point to note is that our users' expectations from BORGES were high but BORGES V2 is not a high precision filtering tool. It sweeps through a broad spectrum of newsgroups and WWW pages, often filtering as many as 27,000 articles in one day, and with such high numbers it is inevitable that there will be more junk than relevant information filtered for a user. This is exacerbated by the fact that the signal to noise ratio in USENET News is very low, it is a low quality information source compared to Reuters newswire or articles from an on-line newspaper. These factors left our user population of internet novices more despondent than we would have liked and in retrospect we now see why this is so. It would have been preferable to include more high-quality information sources into BORGES and for the low-quality information sources, to allow each user profile to selectively filter only portions of the total newsgroup set. Doing this, however, is something that we would not expect the naïve user to do so the sourcing of information sources to be filtered could be part of the service offered by the library as part of BORGES filtering.
At the start of the project we anticipated including many advanced features of information retrieval into BORGES but the library partners, representing the user population, kept us firmly reined in. There is no point incorporating any kind of advanced IR technique into BORGES when it overly complicates the user's model of how to use the system, unless the payback is a significant improvement in effectiveness. Our user population represents the typical user population served by a University library and many of them were not internet-aware and certainly most were not familiar with the subtleties of using USENET News. For us as developers it would have been very interesting to add user-controlled term weighting, relevance feedback, selective user-controlled query expansion, etc., to our operational system but most users simply did not want to know about these things even if they do improve the quality of articles filtered. Our users want things kept simple, and that is what we did when making the query expansion transparent to them. That is not to say that the more advanced information retrieval techniques are not useful to users, they are, but they would not necessarily have been of use to our users most of whom were first-time users of News and WWW.
It is clear that the progress in the BORGES project was overtaken by technical developments. Developments such as the advent of Java applets, HTML standardisation and increased plug-ins becoming available, web based resource monitoring, VRML and the emergence of WWW search engines as well as the emergence of information sources to be filtered which have a more attractive signal/noise ration than USENET or WWW, have all contributed to changing the landscape in which the BORGES project operated. If we were to start BORGES now, in late 1996, the implemented system would probably have to be very different in order to take these developments into account. Much greater use would be made of the existing and much more exhaustive indexes on WWW and perhaps WWW pages would not be downloaded into BORGES for matching against profiles but AltaVista, Lycos or Infoseek or even a combination of these [Smeaton and Crimmins, 1997], would be used for this.
In BORGES we used SMART to build an inverted file for a cache of WWW and News articles in order to allow the user to use the "Try this profile now" button shown in Figure 2. This facility was put in place to allow users to interactively refine their profiles by examining the output of profile changes in terms of the previous batch of filtered documents. In practice the facility was hardly used by our users. A much more appropriate system architecture for an information filtering service would build profiles and match incoming documents against all profiles treating the profiles as documents and the documents as queries. Frequency distributions for terms in profiles could be gathered over time and such an architecture would allow a faster filtering operation. New terms appearing in a user profile would initially be assigned high weights until their true frequencies of occurrence can be established. The frequency distribution of such new terms has been shown to be estimable within a relatively small number of filtered documents [Callan, 1996] and the advantages of such an arrangement are that changes to user profiles take effect immediately the profiles are re-indexed (a computationally lightweight operation) and users can be informed about filtered documents as soon as they are retrieved into the filtering system rather than after the next batch run, i.e. the filtering can be a continuous operation.
Finally, the role of the (University) library in an information filtering task remains important and we believe BORGES has shown this. Unless the total information source is reduced and constrained in some way in order to improve the quality of information filtered for the user, the user will become disenchanted with the filtering service as has happened to some users in BORGES. The need for an expert to help users formulate their profiles and to restrict the scope of their filtering operation for them so the signal to noise ratio is improved, is clear.
References
[Callan, 1996] "Document Filtering with Inference Networks", J. Callan, in [SIGIR, 1996], pp262-269.
[Croft, 1995] " What Do People Want from Information Retrieval? ", W.B. Croft, D-lib Magazine, November 1995,
[Hollands, 1996] " Keeping Track of Changes to Web-Based Resources ", P Hollands, Ariadne Magazine, May 1996.
[Miller, 1995] "WordNet: A Lexical Database for English", G.A. Miller, Communications of the ACM, 38(11), 39- 41, 1995.
[Smeaton et al., 1996] A.F. Smeaton, F. Kelledy and R. O'Donnell, "Thresholding Postings Lists, Query Expansion by Word-Word Distances and POS Tagging of Spanish Texts", in Proceedings of TREC-4, D. Harman (Ed), NIST Special Publication, 1996.
[Smeaton and Crimmins, 1997] A.F. Smeaton and F. Crimmons, "Using Data Fusion Techniques for Searching the WWW", submitted to WWW6 Conference, April 1997.