COPAC: The New Nationally Accessible Union Catalogue
1. Introduction
COPAC is a new consolidated union catalogue which provides free access to a database of records provided by members of the Consortium of University Research Libraries (CURL). The CURL database has been in existence since 1987, permitting record exchange between member libraries and providing a reference service to library staff, and it has long been felt that the database would be of value to the wider academic community. COPAC is the product of a JISC funded project to make the CURL database accessible to the research community as a whole.
COPAC was launched in April 1996. Initially a Text interface was provided, with a Web interface being introduced shortly afterwards. The project was working to a very tight schedule so it was decided to produce a basic system which worked well, rather than try anything too ambitious in the early stages. If the user feedback on the early system is anything to go by, then the project team achieved this goal, as the general response to COPAC has been very positive, the major complaint relating to the desire for records from more libraries to be included in the database.
2. The data
The COPAC database contains the records from the main online library catalogues of:
- Cambridge University
- Edinburgh University
- Glasgow University
- Leeds University
- Oxford University
- Trinity College Dublin
The records from a further fourteen member libraries will be added in due course, with the possibility of records from more libraries to be added in the future.
Obviously, the presence of records from many libraries results in considerable record duplication which is extremely undesirable in an end-user system. To overcome this problem, record matching and consolidation routines are employed to eliminate as much duplication as possible. This results in the production of consolidated records which provide merged bibliographic details alongside individual library holdings, where the latter are available.
Matching is based on two relatively simple algorithms. Initial matches are identified using ISBN or ISSN, or author/title 4⁄4 keys and date (eg. Tolk/Lord,1990 = Tolkien, Lord of the Rings, 1990). These potential matches are then verified using a number of additional field comparisons. This approach has resulted in considerable success in matching duplicate records, reducing database size from c. 5.5 million to c. 3.5 million records.
Inevitably there have been problems with the duplicate detection process. Cataloguing variations between libraries, changes in cataloguing standards over time, and data errors, all mean that for some records automatic duplicate matching is not possible. Human intervention would undoubtedly identify further duplicates, but the project does not have the resources for this type of editorial control and some duplication will remain. If the matching criteria were made more liberal then it would be possible to increase the number of duplicates detected, but this would also result in the incorrect matching of records. The presence of some duplicate records is preferable to misleading consolidation, so the matching mechanism is designed to err on the side of caution [1]. The resulting consolidated record is illustrated in fig 1, which shows a record produced by the merger of two records originating from Dublin and Cambridge.
Main Author: Tolkien, J. R. R. (John Ronald Reuel), 1892-1973
Title details: The hobbit, or, There and back again / [by] J.R.R. Tolkien ; illustrated by the author
Publisher: London [etc.] : Unwin Paperbacks, 1979
Physical Desc.: 287p : ill, maps ; 18cm, Pbk
ISBN/ISSN: 0048231541
Notes: This ed. originally published: 1975
Subject(s): Children’s stories in English, 1900- Texts
Document Type: Fiction
Language: English
Local Holdings:
Cambridge - contact Cambridge University Library ; 9720.d.6196, 1990.7.3859
(unbound copy);
Dublin - Trinity College Library ; PB- 18-634, PB- 32-260;
Fig. 1. Example of consolidated record.
3. The COPAC interfaces
COPAC is accessible using both a Text Interface and Web Interface to ensure it is available to as many potential users as possible. The principle underlying COPAC interface design has been to keep the user interaction as simple as possible, whilst providing behind the scenes support for the search process. Both interfaces utilise the same basic approach, a mix of form filling and menu choices. However, there are differences as the Text interface offers a wider range of facilities. These differences arise from the way in which the interfaces were produced. The Text interface was written in-house, giving us considerable control over its appearance and functionality. In contrast, time constraints made it necessary to produce the Web interface using commercial software. Inevitably, this is not tailored to the requirements of a specific service and it has been impossible to provide all the facilities which we would like to introduce. We are waiting for the delayed release of the next version of the software to investigate whether this will permit us to add some of the missing features.
The COPAC main menu offers three search options, author/title, periodical and subject search. Limiting the number of menu options helps to reduce the amount of decision making which the user has to make at this early stage of the search. When a menu option is chosen the user is presented with a form containing labelled fields into which search terms may be entered. The search logs have recorded a few users who obviously felt that search terms must be entered into every field, but this is very uncommon and as a rule there appears to be no difficulty with this approach. The search form for the Author/Title search on the Web interface is illustrated in fig 2.
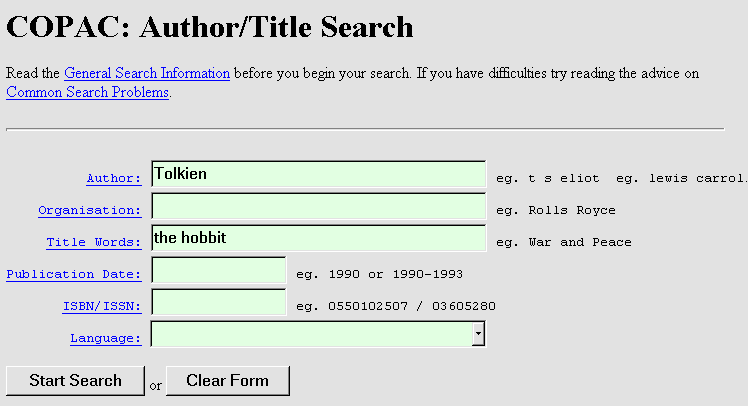
Fig 2. The Author/Title search form on the COPAC Web interface
Alongside the search forms, menus offer the user a range of choices, for example different display formats. The two main facilities which are exclusive to the Text interface are the ability to tag and download records. Tagging can be used for selective display of full records from a retrieved set, as well as for selective downloading of records via email. Downloading is obviously possible in the Web interface using a browser’s own facilities, but this means full records can only be downloaded singly as they display one to a page.
4. Retrieval mechanism
The initial retrieval mechanism used in COPAC was the automatic combination of search terms using Boolean AND. This has an obvious disadvantage. Boolean AND reduces search set size and when working with the limited amount of text available in an OPAC record this can mean reducing the set to zero. Indeed, the search logs indicate that there are significant numbers of searches which fail to retrieve any records. At the other extreme, some users enter very general search terms which retrieve large numbers of records. Both these situations are being addressed in retrieval mechanism developments in the Text interface, and will be reflected in the Web interface in due course.
4.1 Increasing search results
Some users will obtain a zero result in response to a search simply because the database does not contain the required document. However, in many other cases the search may fail for reasons such as spelling errors (by either user or cataloguer), mistakes in remembering the correct document details for a known item search, and typing in a subject which is more detailed than the subject information available in the records.
4.1.1 Word lists
COPAC does not use a spell-checker, but an attempt has been made to handle title words unrecognised by the system. Any word which is not in the index results in the user being offered the opportunity to browse a word list. The unrecognised search word is truncated to the first five characters and all matching words displayed, as illustrated in fig. 3. The user may select one or more words from the list to incorporate into the search. These new terms are combined automatically using Boolean OR.
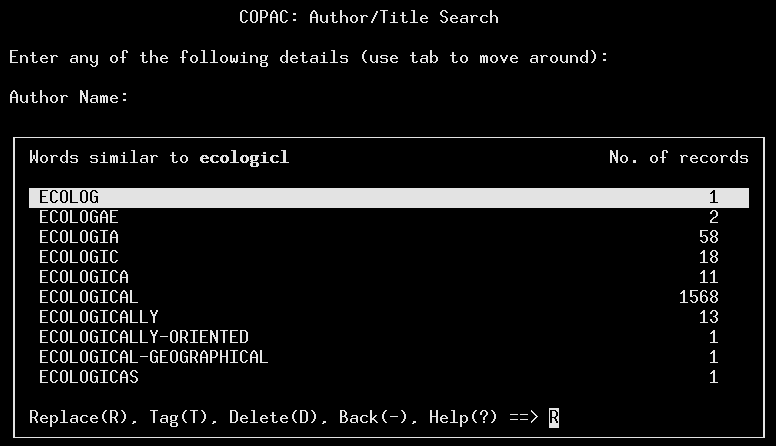
Fig. 3. An example of the Word List.
Obviously, there are occasions where the user makes a spelling mistake in such a way that no words are found in the index which match the word stem eg. ‘Bronte’ entered as ‘Brnte’. Even so the act of drawing attention to the unknown word should increase the likelihood that the user will identify and correct a mistake.
4.1.2 Tree searching
Many searches fail, not because of spelling errors, but because the user has failed to match the wording used in the records representing relevant materials. A different approach is required in these cases. To try to improve search success tree searching [2] has been introduced into the title field search and is due to be incorporated into subject field and multi-field searching shortly. Tree searching allows the selective implementation of successively broader search definitions in order to maximise retrieval results. This first involves the use of phrase and keyword searching to form an initial result set. If this fails to achieve a threshold number of records then additional search procedures are brought into play, such as dropping the search term with the highest number of postings in the database or dropping one element of a multi-field search. For example, users sometimes enter information in several fields in addition to entering an ISBN. Where the ISBN element fails the search could continue with the remaining elements.
Tree searching has a further benefit as it permits the ranking of retrieved records on the basis of likely relevance. This makes it easier to review a set of retrieved records, as the user can stop browsing when the relevance of the records appears to be declining.
Obviously, the user who enters correctly the title of a novel is unlikely to benefit from this type of search enhancement, as the search should be quite precise and any additional materials retrieved through the tree-search will probably not be relevant. However, the tree-search should not be detrimental to such a search, as tests indicate that the required document should occur at the top of the ranked list. In other circumstances the tree-search can produce some very useful results. For example, where the title is being used for subject searching or where an error has been made by cataloguer or user when entering document details. The possibility of making some elements of the search tree optional is being considered. This would give the user greater control over the way the search is conducted, but would have the disadvantage of complicating the user interaction and slowing the overall search time.
4.2 Search refinement
Just because a user finds records in response to a query the search cannot necessarily be defined as a success. Some users retrieve hundreds, or even thousands, of records by entering a very general query statement, whilst others find that most of the records retrieved are not a good reflection of the real search requirement. Interestingly, tree-searching can provide some support for the user who finds large numbers of records. Although a large record set retrieved using tree-searching will probably be the same as would be found using Boolean AND, the records will be ranked in order of likely relevance. Whilst this may not always be useful, tests suggest that in many cases it results in a much more helpful ordering of retrieved material than can be achieved by, for example, an author and title sort mechanism.
In the future, mechanisms for relevance feedback and search refinement will be considered to enable COPAC to support users who are retrieving large record sets. However, it is important to ensure that in trying to provide user support the interface is not becoming so complicated that it results in a significant reduction in the ease of use of the system.
5. Further developments
5.1 Inter-Library Loans
The ability for a researcher to order an inter-library loan (ILL) via COPAC would add considerable value to the service, and this is a feature in which users have expressed interest. A review of ILL and document delivery issues has been conducted, and the results are currently under consideration by the CURL libraries. Initially any such service would concentrate on the lending of returnable materials, whilst document delivery of photocopies etc. might also be a possibility at a later date.
In the meantime, during 1997 a trial ILL service will be established between a selection of CURL and non-CURL libraries. This will be available only to library staff, using COPAC to mediate ILL requests via email. Its main purpose is to examine some of the organisational and economic issues associated with the establishment of an ILL service. Links will also be developed with relevant eLib projects to ensure that work on the technical aspects of an ILL and document delivery service is not duplicated.
5.2 Z39.50
A COPAC Z39.50 target is under active development and a test version is available [3]. This is still in its early stages and we would appreciate feedback from searchers on both success and failure when accessing COPAC by this route. It should be emphasised that it is not possible to display MARC records from COPAC, so some Z39.50 origins will fail as they will only handle MARC records.
Longer term development is likely to include production of a COPAC Z39.50 origin. This would be designed to act as a Web/Z gateway and would make it easier to provide the user who accesses COPAC via the Web with the same functionality as that provided in the Text interface. In addition the COPAC Z39.50 origin could provide links to other catalogues and information services of potential interest to the researcher.
6. Summary
COPAC is a union catalogue providing free end-user access to the online catalogues of some of the largest research libraries in the UK and Ireland. It is intended that, in time, all CURL member libraries will provide their catalogue data for inclusion into COPAC. Obtaining records from such a range of libraries obviously brings with it the problem of record duplication within the COPAC database. Duplicate matching and record consolidation procedures have been implemented to minimise this problem, but some duplicates will remain as there is no human editorial input into this process.
COPAC is accessible via two easy to use interfaces:
To enhance search results a variety of mechanisms are being considered, with word lists and tree searching currently being introduced in the Text Interface. Z39.50 offers the possibility of providing another means of accessing COPAC and a test target is already available.
A significant development for the longer time may be the introduction of ILL facilities mediated by COPAC. This is currently being considered by the CURL libraries, and mechanisms for supporting such a service are being examined.
References
- A more detailed description of the consolidation process is available in: S.A. Cousins, COPAC: the CURL OPAC., Program 31(1) 1997, 1-21.
- The use of search trees was first discussed in relation to the Okapi project: N.N. Mitev, G.M.Venner & S. Walker, Designing an online public access catalogue: Okapi, a catalogue on a local area network. Library and Information Research Report 39. London: British Library, 1985.
- COPAC’s Z39.50 target; details of the test version of the COPAC Z39.50 target,
http://copac.ac.uk/~zzaascs/z39.50.html - COPAC Web Interface,
http://copac.ac.uk/copac/ - COPAC Telnet Interface,
telnet copac.ac.uk, use username and password copac
Author Details
Shirley Cousins
OPAC developer, COPAC Project.
Email: copac@mcc.ac.uk
COPAC is based at Manchester Computing, University of Manchester